09. 안전하게 카펜터를 사용하는 방법

카펜터는 노드의 비용을 최적화하기 위하여 노드의 수량을 적극적으로 변경합니다. 신규 파드를 생성하기 위하여 새로운 노드가 실행되면 파드에 설정된 ‘Request’ 용량에 따라 가장 비용이 저렴한 노드를 신규로 생성하고 기존 노드 중 사용량이 낮은 노드는 삭제하여 기존 노드에 실행 중인 파드를 새로운 노드로 이전합니다. 이러한 작업동안 기존 파드는 삭제되고 새로운 파드가 시작하는데, 파드가 재시작되어도 고객 서비스에 영향을 미치지 않기 위하여 ‘TerminationGracePeriodSeconds’, ‘PodDisruptionBudget’, ‘PriorityClass’ 등의 옵션이 필요합니다. 이번 장에서는 해당 옵션을 알아봅니다.
1. Graceful Shutdown(안정적인 종료)
사용자의 증가, 감소에 따라 파드 오토스케일링이 발생하여 노드 수량이 증가, 감소하면 카펜터는 비용을 최적화하도록 노드의 수량과 타입을 변경합니다.
이전 클러스터 오토스케일러에 비하여 보다 잦은 노드 수량이 변경됩니다. 카펜터가 자동으로 노드를 변경하여 EC2 노드 비용이 이전에 비하여 약 30% 감소하였습니다. 하지만 노드가 종료되면 노드에 실행 중인 파드도 같이 종료되어 서비스에 영향을 미칠 수 있습니다. 따라서 파드가 안전하게 종료될 수 있도록 설정이 필요합니다.
쿠버네티스는 노드(혹은 사용자)가 종료(Terminating) 신호를 받으면 파드는 아래의 프로세스에 따라 파드를 종료합니다.
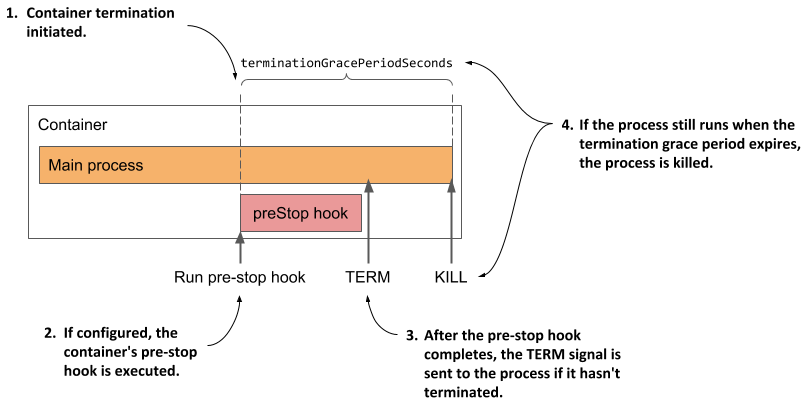
- 사용자, 노드 등에서 종료 신호(terminating) 신호를 받으면 해당 파드는 서비스 엔드포인트(endpoint)에서 제외되어 새로운 요청을 받지 않습니다. 그리고 컨트롤 플레인의 ‘etcd’ 데이터베이스에도 해당 노드의 상태는 ‘terminating’ 상태로 변경됩니다.
- 파드가 terminating 상태로 전환되면, Kubernetes는 파드 내의 모든 컨테이너에게 ‘preStop’ 핸들러를 실행하도록 요청합니다. preStop 핸들러는 파드가 종료되기 전에 컨테이너가 수행해야 할 정리 작업들을 실행하는 데 사용됩니다. 예를 들어, 컨테이너가 데이터베이스에 변경 사항을 저장하는 등 종료 준비를 할 수 있습니다. preStop 설정은 매니페스트에 별도로 지정해야 합니다.
- preStop 핸들러 실행이 완료되면, 쿠버네티스는 해당 파드의 모든 컨테이너에게 SIGTERM 시그널을 보냅니다. SIGTERM은 graceful shutdown을 위한 시그널로, 컨테이너에게 프로세스를 종료하도록 요청합니다. 이 시그널을 받은 컨테이너는 preStop 정리 작업을 마치고 자연스럽게 종료하려고 시도합니다.
- 파드는 이 후 ‘terminationGracePeriodSeconds’에 지정된 시간 동안 대기합니다. 이 시간 동안 컨테이너는 종료 준비를 마치려고 노력하며, 해당 시간 내에 종료되지 않으면 파드는 강제로 종료됩니다. 파드의 기본 ‘terminationGracePeriodSeconds’ 설정 시간은 30초 입니다. 30초 이상의 시간이 필요하면 YAML 파일 설정에서 변경합니다. 필자는 4시간을 설정하기도 합니다.
- ‘terminationGracePeriodSeconds’ 시간이 지난 후에도 컨테이너가 종료되지 않으면, 쿠버네티스는 ‘SIGKILL’ 시그널을 보내서 강제로 컨테이너를 종료합니다. ‘SIGKILL’은 강제 종료 시그널로, 컨테이너가 정해진 시간에 종료되지 않을 경우 사용됩니다.
기존 세션이 유지되어야 하는 VoIP 등의 전화 서비스의 경우 세션을 정상 종료해야 합니다. 만약 카펜터에 의하여 노드가 종료되어 파드가 비정상 종료되면 사용자의 전화가 끊어지므로 장애 상황입니다. 전화하고 있는 고객의 서비스 세션을 끝까지 유지하는게 필요합니다. 따라서 이와 같은 서비스의 설정은 1) VoIP 등 전화 통화와 관련 파드는 별도 전용 노드에서 실행하고 2) 파드가 종료되는 ‘terminationGracePeriodSeconds’ 시간 설정을 4시간(14,400s) 등으로 넉넉하게 설정하여 모드 세션을 정상 종료하고 파드가 종료하도록 설정합니다. 파드가 종료 신호를 받아도 4시간의 추가 시간을 두어 해당 시간에 기존 통화가 종료되도록 기다립니다.
예시로 알아봅니다.
busybox-graceful-shutdown-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: pods-termination-grace-period-seconds
spec:
containers:
- command:
- sleep
- "3600"
image: busybox
name: pods-termination-grace-period-seconds
terminationGracePeriodSeconds: 5 # Time to wait before moving from a TERM signal to the pod's main process to a KILL signal.
terminationGracePeriodSeconds 시간을 5초로 지정하였습니다. 해당 파드는 종료 요청을 받으면 바로 삭제되지 않고 5초 동안 정상 종료될 때까지 기다렸다가 삭제합니다. 파드를 종료하여 5초동안 유지하는지 알아봅니다.
해당 busybox 파드를 실행합니다.
(jerry-test:default)k8s-class:jerry$ cd karpenter/ (jerry-test:default)k8s-class:jerry$ k apply -f busybox-graceful-shutdown-pod.yaml pod/pods-termination-grace-period-seconds created
파드를 종료하고 다른 창에서 ‘k get pod -w(wait)’ 명령어를 사용하여 실시간으로 파드의 변경 사항을 확인합니다.
(jerry-test:default)k8s-class:jerry$ k delete pod pods-termination-grace-period-seconds pod "pods-termination-grace-period-seconds" deleted
(jerry-test:default)k8s-class:jerry$ k get pod -w NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pods-termination-grace-period-seconds 1/1 Running 0 3s 10.110.42.118 ip-10-110-47-109.ap-southeast-1.compute.internal <none> <none> pods-termination-grace-period-seconds 1/1 Terminating 0 14s 10.110.42.118 ip-10-110-47-109.ap-southeast-1.compute.internal <none> <none> pods-termination-grace-period-seconds 0/1 Terminating 0 20s 10.110.42.118 ip-10-110-47-109.ap-southeast-1.compute.internal <none> <none>
위에서 확인할 수 있듯이 Terminating(1/1) 명령을 받고 5초 후에 완전히 종료 Terminating(0/1)되었습니다. 바로 종료되지 않고 5초의 유예 시간을 유지합니다. 위와 같이 기존 세션을 유지해야 하는 서비스는 ‘terminationGracePeriodSeconds’ 옵션을 설정하여 필요한 시간만큼 기존 서비스가 완전히 정상 종료되기를 기다리도록 합니다.
필자는 파드가 종료되어도 기존 세션을 유지해야 하는 전체 서비스 파드에 Graceful Shutdown 설정을 추가하였습니다.
2. PodDisruptionBudget 설정
카펜터가 노드를 중단하면 해당 노드에 실행 중인 파드는 종료되고 다른 노드에서 새로운 파드가 실행됩니다. 종료 명령을 받은 파드는 먼저 Terminating 상태로 들어가고 다음 실행 가능한 다른 노드에서 실행(Running)됩니다. 먼저 Terminating 되고 다음 파드를 실행하므로 기존 파드가 종료되고 새로운 파드가 실행하는 시간(Terminating -> Running)동안 서비스 중단 현상이 발생할 수 있습니다. 순단이지만 서비스 중단은 장애이므로 서비스 중단이 발생하지 않도록 쿠버네티스에서 PodDisruptionBudget(파드 중단 예산) 설정을 추가할 수 있습니다.
PodDisruptionBudget(이하 PDB)은 파드의 중단을 제어하는 정책입니다. PDB를 사용하면 클러스터 내의 파드 중단 시점에 대한 제한을 설정하여, 특정 파드가 중단되는 동안 애플리케이션의 가용성과 안정성을 유지할 수 있습니다.
PDB를 이해하기 위해 다음과 같은 시나리오를 생각해봅시다.
가정:
- 클러스터에 웹 서비스를 제공하는 3개의 파드가 있습니다.
- 이 서비스는 가용성을 위해 3개의 파드가 모두 작동 중이어야 합니다.
- 만약 2개 이상의 파드가 동시에 중단된다면, 서비스가 중단되거나 장애가 발생할 수 있습니다.
이런 상황을 방지하기 위해 PDB를 사용합니다. PDB를 설정하여 다음 규칙을 정의할 수 있습니다:
- MinAvailable: 최소한으로 유지해야 하는 파드의 개수를 지정합니다. 예를 들어, MinAvailable: 2로 설정하면 최소 2개의 파드가 항상 작동 중이어야 합니다.
- MaxUnavailable: 동시에 중단될 수 있는 최대 파드의 개수를 지정합니다. 예를 들어, ‘MaxUnavailable: 1’로 설정하면 동시에 1개의 파드만 중단할 수 있습니다.
위와 같이 서비스 특성에 맞게 PDB를 적절하게 설정하여 안정적으로 서비스를 제공할 수 있습니다.
그럼, 실습으로 알아봅니다. 실습 시나리오는 하나의 노드에 2개의 파드를 실행하고 해당 파드에 PDB를 설정합니다. 해당 노드를 Drain(다른 노드로 이전)하여 해당 노드의 파드를 다른 노드로 이동합니다. 이때 PDB를 설정하면 하나(minAvailable)의 파드는 넘어가지 않고 해당 노드에서 계속 실행됩니다.
먼저 실습 용 Deployment 리소스를 정의합니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: busybox
labels:
app: busybox
spec:
replicas: 2
selector:
matchLabels:
app: busybox
template:
metadata:
labels:
app: busybox
spec:
containers:
- command:
- sleep
- "3600"
image: busybox
name: busybox
nodeSelector:
kubernetes.io/hostname: ip-10-110-47-109.ap-southeast-1.compute.internal
기존에 사용한 Busybox Deployment 매니페스트와 동일하지만 ‘nodeSelector’ 옵션을 추가하였습니다. nodeSelector는 이름에서 유추할 수 있듯이 지정한 노드에 파드를 실행하는 옵션입니다. 위 예시는 특정 호스트네임을 갖는 노드(ip-10-110-47-109.ap-southeast-1.compute.internal)에 파드를 실행하는 설정입니다. 각자 EKS 노드의 호스트 네임을 입력하여 매니페스트 파일을 수정합니다.
PDB 역시 쿠버네티스 리소스로 YAML 파일로 실행할 수 있습니다. 설정은 아래와 같이 매우 간단합니다.
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: busybox
namespace: default
spec:
minAvailable: 1
selector:
matchLabels:
app: busybox
. spec.minAvailable: 1
최소 가용한 파드의 개수입니다. 파드가 종료되어도 항상 최소한 실행되어야 하는 파드의 수량입니다. 애플리케이션 특성에 따라 적절하게 수량을 조정합니다.
. spec.selector.matchLabels
PDB를 적용하는 파드를 지정합니다. 서비스 리소스가 파드를 지정할 때 selector를 사용하는 것과 동일하게 Label 기준으로 Target 파드를 지정합니다.
위 2개의 리소스를 배포합니다.
(jerry-test:default)k8s-class:jerry$ cd podDisruptionBudget/ (jerry-test:default)k8s-class:jerry$ k apply -f busybox-pdb.yaml -f busybox-nodeSelector-deploy.yaml poddisruptionbudget.policy/busybox created deployment.apps/busybox created
‘PodDisruptionBudget’은 쿠버네티스 리소스로 아래 명령어로 확인할 수 있습니다.
(jerry-test:default)k8s-class:jerry$ k get pdb NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE busybox 1 N/A
상세한 정보를 확인합니다.
(jerry-test:default)k8s-class:jerry$ k describe pdb busybox
Name: busybox
Namespace: default
Min available: 1
Selector: app=busybox
Status:
Allowed disruptions: 1
Current: 2
Desired: 1
Total: 2
(생략)
. Selector
Label(app=busybox) 기준으로 PDB가 적용될 리소스를 선택하였습니다.
. Status: Allowed disruptions: 1
중단(disruptions) 가능한 파드의 수량이 ‘1’입니다. Target 대상인 busybox 파드를 1개까지 종료할 수 있습니다.
PDB, 디플로이먼트 리소스가 실행 중입니다. 이제 노드를 종료하여 PDB가 정상 동작하는지 확인합니다. 노드에 실행 중인 파드를 다른 노드로 강제 이동하는 ‘drain’ 명령어를 사용합니다.
카펜터는 노드의 수량을 최적화하는 ‘consolidation’(통합) 과정을 진행하면 해당 노드에 파드를 실행하지 못하도록 막고(cordon) 해당 노드의 파드를 다른 노드로 이동(drain)하는 단계를 진행합니다. 해당 상황을 재현하기 위하여 busybox 파드가 실행 중인 노드를 drain 합니다.
먼저, 파드가 실행 중인 노드 정보를 확인합니다.
(jerry-test:default)k8s-class:jerry$ k get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES busybox-5784bfcbcd-2p9cj 1/1 Running 0 8m31s 10.110.37.91 ip-10-110-47-109.ap-southeast-1.compute.internal <none> <none> busybox-5784bfcbcd-gnf9l 1/1 Running 0 8m31s 10.110.39.167 ip-10-110-47-109.ap-southeast-1.compute.internal <none> <none>
nodeSelector 설정으로 2개의 파드 모두 ip-10-110-47-109.ap-southeast-1.compute.internal 노드에서 실행 중입니다. 해당 노드를 drain 합니다. k drain 명령어 수행 시 –ignore-daemonsets, –delete-emptydir-data 옵션을 추가합니다.
(jerry-test:default)k8s-class:jerry$ k drain ip-10-110-47-109.ap-southeast-1.compute.internal --ignore-daemonsets --delete-emptydir-data node/ip-10-110-47-109.ap-southeast-1.compute.internal cordoned (생략) error when evicting pods/"busybox-5784bfcbcd-2p9cj" -n "default" (will retry after 5s): Cannot evict pod as it would violate the pod's disruption budget. (생략) error when evicting pods/"busybox-5784bfcbcd-2p9cj" -n "default" (will retry after 5s): Cannot evict pod as it would violate the pod's disruption budget. (생략)
–ignore-daemonsets은 해당 노드에서 실행 중인 데몬셋 파드를 종료하는 옵션이고 –delete-emptydir-data는 특정 파드가 노드의 임시 디렉토리를 사용하는데 노드가 삭제되면 해당 데이터를 사용하지 못한다는 경고 메세지입니다. 다른 노드에서 파드가 재시작되어도 되는 파드임을 확인하고 해당 옵션을 추가하여 명령어를 수행합니다.
drain 명령어 실행 시 출력되는 메시지를 확인하면 ‘busybox-5784bfcbcd-2p9cj’ 파드가 Evict(축출) 즉 다른 노드로 이동할 수 없다고 합니다. PDB 설정으로 하나의 파드는 반드시 실행되어야 하므로 다른 노드로 해당 파드가 이동하지 못한다는 의미입니다.
다른 터미널 창에서 확인하면 하나의 busybox 파드는 계속 실행 중 입니다.
(jerry-test:default)k8s-class:jerry$ k get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES busybox-5784bfcbcd-2p9cj 1/1 Running 0 12m 10.110.37.91 ip-10-110-47-109.ap-southeast-1.compute.internal <none> <none> busybox-5784bfcbcd-5d4cc 0/1 Pending 0 2m24s <none> <none> <none> <none>
이와 같이 PDB를 설정하면 카펜터가 노드를 종료하여도 minAvailable 설정에 해당하는 파드는 반드시 실행됩니다. 서비스를 안정적으로 운영하기 위해 꼭 필요한 기본 설정으로 필자는 해당 설정을 실 운영 환경 서비스에 사용하고 있습니다. 카펜터 사용 환경에서 반드시 설정하기 권고하는 옵션입니다. 다음은 실습에 사용한 drain 등 노드 스케쥴링에 관한 명령어를 보다 자세히 알아보겠습니다.
3. 노드 스케줄링 설정 – drain, cordon, uncordon
쿠버네티스는 클러스터의 노드를 유연하게 관리하고, 파드의 이동과 스케줄링을 조절하여 안정성과 가용성을 보장할 수 있도록 ‘drain, ‘cordon’, ‘uncordon’ 명령어를 지원합니다.
drain 명령은 노드를 안전하게 비활성화하고, 해당 노드의 파드를 다른 노드로 마이그레이션하는데 사용합니다. 이는 노드의 정비, 클러스터 버전 업그레이드, 노드의 장애 등의 상황에서 매우 유용합니다. 실무에서 특정 노드에 장애가 발생하여 해당 노드의 파드를 다른 노드로 옮기거나 클러스터 버전을 업그레이드 할 때 사용합니다. (drain 실습은 위에서 진행하여 추가 진행하지 않습니다.)
다음으로 ‘cordon/uncordon’ 명령은 노드의 스케줄링 상태를 조절하기 위해 사용하는는 명령어입니다. 노드의 스케줄링 상태를 변경하여 새로운 파드의 스케줄링을 허용하거나 막을 수 있습니다. 노드를 cordon하면 해당 노드에 더 이상 새로운 파드가 스케줄링되지 않습니다. cordon은 주로 노드의 장애, 정비, 업그레이드 등으로 인해 해당 노드를 일시적으로 사용하지 않고자 할 때 사용합니다.
cordon 작업이 종료되면 uncordon 명령어를 수행합니다. cordon으로 스케줄링이 중단된 노드를 다시 활성화하여, 해당 노드에 새로운 파드의 스케줄링을 다시 허용합니다. cordon 상태에서 노드를 장애로부터 회복하거나, 정비가 완료되어 다시 사용 가능하게 만들기 위해 uncordon 명령어를 사용합니다.
위 PDB 테스트를 완료하여 노드에 새로운 파드가 스케쥴링 되도록 하기 위하여 uncordon 명령을 수행할 수 있습니다.
먼저, 노드의 상태를 확인합니다. ip-10-110-47-109-* 노드는 drain 명령어 수행 후 현재 ‘SchedulingDisabled’ 상태입니다.
(jerry-test:default)k8s-class:jerry$ k get nodes -o wide ip-10-110-47-109.ap-southeast-1.compute.internal k NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME ip-10-110-47-109.ap-southeast-1.compute.internal Ready,SchedulingDisabled <none> 8d v1.26.4-eks-0a21954 10.110.47.109 <none> Amazon Linux 2 5.10.178-162.673.amzn2.x86_64 containerd://1.6.19
테스트가 완료되었으므로 uncordon 명령어로 해당 노드의 cordon 상태를 해제합니다.
(jerry-test:default)k8s-class:jerry$ k uncordon ip-10-110-47-109.ap-southeast-1.compute.internal node/ip-10-110-47-109.ap-southeast-1.compute.internal uncordoned
노드를 확인하면 다시 파드를 실행할 수 있는 상태(Ready)가 되었습니다.
(jerry-test:default)k8s-class:jerry$ k get nodes -o wide ip-10-110-47-109.ap-southeast-1.compute.internal NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME ip-10-110-47-109.ap-southeast-1.compute.internal Ready <none> 8d v1.26.4-eks-0a21954 10.110.47.109 <none> Amazon Linux 2 5.10.178-162.673.amzn2.x86_64 containerd://1.6.19
‘uncordon’ 명령어가 정상으로 실행되었습니다.
이번 장에서는 카펜터를 적용한 상태에서 안전하게 파드를 종료할 수 있는 Graceful Shutdown, Pod Disruption Budget과 추가로 노드 ‘drain, cordon/uncordon’을 알아보았습니다.
PDB 테스트가 완료되어 디플로이먼트와 PDB 설정을 삭제합니다.
(jerry-test:default)k8s-class:jerry$ k delete deployments.apps busybox k ddeployment.apps "busybox" deleted (jerry-test:default)k8s-class:jerry$ k delete pdb busybox poddisruptionbudget.policy "busybox" deleted
해당 기술 블로그에 질문이 있으시면 언제든지 문의해 주세요. 직접 답변해 드립니다.
k8sqna@jennifersoft.com
1. 참고로 ‘kubectl rollout restart {deploy_name}’ 명령어를 실행하면 먼저 파드를 실행(running)하고 실행이 완료되면 기존 파드를 종료(terminating) 상태로 변경합니다.
2. PDB 자세한 설명 – https://kubernetes.io/docs/tasks/run-application/configure-pdb/
3. nodeSelector에 대한 자세한 설명은 다음장 advancedScheduling에서 다룹니다.
