14. 프로메테우스 – 쿠버네티스 모니터링 시스템

이번 장은 오픈소스 모니터링 시스템 프로메테우스를 알아봅니다. 내용에 앞서 쿠버네티스 환경의 모니터링은 전통적인 VM(가상 머신) 환경의 모니터링과 어떠한 차이점이 있는지 알아보겠습니다. 기존 환경과 어떻게 다른지를 알면 조금 더 이해에 도움이 됩니다.
동적 환경 – 쿠버네티스는 컨테이너화된 애플리케이션을 동적으로 스케줄링하고 관리합니다. 이는 파드의 생성, 소멸, 이동이 기존 VM에 비하여 훨씬 빈번합니다. 따라서 실시간으로 변화하는 리소스와 네트워크 토폴로지를 모니터링해야 합니다.
서비스 메트릭 – 쿠버네티스 환경의 모니터링 단위는 기본이 파드이며 파드는 곧 애플리케이션 프로세스를 의미합니다. 따라서 기본 단위가 VM(OS 단위) 환경에 비하여 좀 더 애플리케이션 및 마이크로 서비스 수준에서의 메트릭이 중요합니다. 서비스 응답 시간, 에러율, 트래픽 패턴 등의 모니터링이 필요합니다.
클러스터 상태 – VM 단위가 아니라 전체 쿠버네티스 클러스터의 Health, 노드 상태, 클러스터 리소스 사용량 등을 지속적으로 모니터링해야 합니다. 그리고 쿠버네티스는 오케스트레이션 및 자동화 기능을 제공합니다. 이는 스케일링, 자동 회복(Self-Healing) 등과 같은 동작을 모니터링하는 것을 포함합니다.
이러한 요소를 고려하여 모니터링 솔루션을 선정하고 쿠버네티스 환경에 적합하게 솔루션을 운영해야 합니다.
1. 프로메테우스 주요 특징
프로메테우스는 이미 2018년 8월에 Kubernetes에 이어 2번째로 CNCF 졸업(Graduated)한 프로젝트로 사실상 쿠버네티스 환경의 오픈소스 모니터링 표준 솔루션입니다. Prometheus 프로젝트는 SoundCloud에서 처음 구축되었으며, 오픈소스 공개 후 많은 회사 및 조직에 의해 채택되어 활발한 개발자 및 사용자 커뮤니티를 형성하였습니다.
쿠버네티스 모니터링 솔루션은 오픈소스(프로메테우스 등)와 국산 제니퍼 소프트, 외산 데이터독(Datadog)/뉴렐릭(New Relic) 등 상용 솔루션으로 분류할 수 있습니다. 모니터링은 서비스 운영 부분에서 가장 중요하고 개별 환경에 따라 요구 사항 역시 많이 다르므로 각자 적합한 솔루션을 선택합니다.
그럼 간략하게 프로메테우스 주요 특징을 알아봅니다.
- 간편한 통합과 운영
Kubernetes와 같은 컨테이너 오케스트레이션 시스템과의 통합이 용이하며, 설치 및 운영이 간편하여 IT 인프라의 모니터링과 관리를 단순화합니다. 기본 구성 요소 설치 뿐만 아니라 모니터링 대시보드, 알람 룰 까지 모두 단일 헬름 차트를 이용하여 설치할 수 있습니다. 아주 강력합니다. - 서비스 디스커버리
동적으로 확장되고 축소되는 쿠버네티스 환경에서 프로메테우스는 개별 모니터링 대상을 서비스 엔드포인트에 등록하여 자동으로 변경 내역을 감지합니다. 서비스 리소스를 생성하면 자동으로 엔드포인트 개체가 등록되는데 해당 엔드포인트를 기준으로 프로메테우스도 모니터링 합니다. - 다양한 애플리케이션 익스포터(experter) 제공
MySQL, Elastic, Kafka, Redis 등 거의 모든 애플리케이션이 프로메테우스에서 사용할 수 있는 메트릭 정보를 제공합니다. 사용자는 애플리케이션 설치 시 별도의 추가 시간을 들이지 않고 익스포터를 이용하여 손쉽게 모니터링 할 수 있습니다. - 자체 검색 언어 PromQL(Prometheus Query Language) 제공
다양한 레이블 사용이 가능한 메트릭을 조회할 수 있도록 프로메테우스는 자체 검색 언어를 제공합니다. 시각화 솔루션 그라파나에서 PromQL으로 다양하게 자료를 조회하여 원하는 그래프 형태로 나타낼 수 있습니다. 뿐만 아니라 로깅 솔루션 로키에서도 비슷한 검색 언어(LogQL)를 사용하여 편의성이 뛰어납니다 - 커뮤니티 및 통합
강력한 커뮤니티 지원과 다양한 서드파티 통합으로, 새로운 기술과 플랫폼에 대한 지원이 지속적으로 확장되고 있습니다. - 사용자 지정 및 유연성
사용자의 특정 요구에 맞게 경고 규칙, 데이터 수집 방법, 저장 기간 등을 맞춤 설정할 수 있어, 다양한 환경과 요구 사항에 유연하게 대응할 수 있습니다. - Pull 방식
변경이 잦은 개별 모니터링 대상을 프로메테우스는 에이전트를 설치하고 에이전트가 중앙 서버로 모니터링 정보를 전달하는(Push) 방식이 아닌 중앙의 프로메테우스 서버가 모니터링 대상의 정보를 직접 가져오는(Pull) 방식을 사용합니다.
모니터링 혹은 관측 가능성(옵져버빌리티)에 필요한 요소는 크게 메트릭, 로그, 트레이싱(추적 정도로 번역할 수 있습니다.) 그 중 프로메테우스는 메트릭(Metric) 모니터링 솔루션입니다. 모니터링에서 사용하는 메트릭(metric)이란 보통 시계열 데이터로 수집되며, IT 인프라의 성능과 관련된 다양한 측면을 정량적으로 나타내는 데 중요한 역할을 합니다. 웹 서버 요청 횟수, 액티브 DB 쿼리 등 애플리케이션의 성능은 숫자로 이루어진 메트릭으로 파악할 수 있습니다. 예를 들어 사용자 응답 속도가 느려졌을 때 관리자는 웹 서버 요청 횟수가 증가하는 메트릭을 확인하여 원인을 빠르게 파악할 수 있습니다.
메트릭은 시간의 흐름에 따라 수집되며, 이를 통해 시스템의 성능 변화, 문제 발생 패턴 등을 시간적 맥락에서 분석할 수 있습니다. 필요한 메트릭을 기반으로 정상 범위를 정의하고, 이를 벗어나면 알람을 발생시켜 문제를 신속하게 인지하고 대응할 수 있습니다. 관리자는 메트릭을 분석함으로써 시스템의 성능 병목 현상을 파악하고, 이를 해결하여 전체 성능을 최적화할 수 있습니다. 모니터링 시스템은 메트릭을 대시보드나 그래프 형태로 시각화하여, 시스템의 현재 상태를 쉽게 파악하고, 장기적인 추세를 분석할 수 있습니다.
쿠버네티스 환경에서 손쉬운 사용을 위하여 프로메테우스 커뮤니티는 프로메테우스-스택 헬름 차트를 제공하고 있습니다. Prometheus 설치에 필요한 다양한 쿠버네티스 매니페스트, 시스템의 메트릭을 시각화하고 모니터링하기 위한 그라파나 대시보드, 데이터 수집 및 처리, 알람 생성 등을 위한 프로메테우스 Rules, 프로메테우스 스택의 설치, 설정, 운영에 도움이 되는 문서와 스크립트, 쿠버네티스 클러스터 내에서 프로메테우스 구성 요소를 관리하기 위한 프로메테우스 오퍼레이터까지 다양한 컴포넌트를 포함하였습니다.
실제 모니터링 시스템을 구축하는 건 많은 시간과 노력이 필요한데 프로메테우스 스택 헬름 차트를 사용하면 손쉽게 구축할 수 있습니다. 대단한 장점이라고 생각합니다.
실습 과제
- Prometheus-Stack 헬름 설치
- Prometheus Node-Exporter 구조 확인
- 애플리케이션 대시보드 구축 – Redis Exporter 이용
깃헙 링크
2. 헬름 프로메테우스 설치
그럼 실습으로 자세한 내용을 알아보겠습니다. 헬름을 이용한 애플리케이션 설치 방법은 앞에서 설명드려 이번 장에서는 간단히 명령어만 나열합니다.
(jerry-test:kubecost)~$ cd k8s-class/prometheus/ (jerry-test:kubecost)prometheus$ helm pull prometheus-community/kube-prometheus-stack (jerry-test:kubecost)prometheus$ tar xvfz kube-prometheus-stack-48.3.1.tgz (jerry-test:kubecost)prometheus$ rm -rf kube-prometheus-stack-48.3.1.tgz (jerry-test:kubecost)prometheus$ mv kube-prometheus-stack kube-prometheus-stack-48.3.1 (jerry-test:kubecost)prometheus$ cd kube-prometheus-stack-48.3.1/ (jerry-test:kubecost)prometheus$ mkdir ci && cp values.yaml ci/
복사한 헬름 values.yaml 파일을 아래와 같이 수정합니다.
grafana:
enabled: true
defaultDashboardsTimezone: Asia/Seoul
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing # or internal
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "my-test"
external-dns.alpha.kubernetes.io/hostname: $GRAFANA_DOMAIN
hosts:
- $GRAFANA_DOMAIN
paths:
- /*
persistence:
type: pvc
enabled: true
accessModes:
- ReadWriteOnce
size: 10Gi
prometheus:
prometheusSpec:
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: 10GiB
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: ebs-sc
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi
. grafana.enabled: true
프로메테우스 스택 헬름 차트를 사용해서 시각화 솔루션인 Grafana까지 추가 설정없이 한번에 설치할 수 있습니다.
. grafana.ingress
AWS LB & External DNS Controller를 사용하여 편리하게 Ingress 구성이 가능합니다.
. ingress.annotations.
alb.ingress.kubernetes.io/scheme: internet-facing # or internal
VPN 설정이 되어 있는 운영 환경에서는 VPC 내부에서만 접근 가능하도록 internal로 변경합니다. 또는 Security Group을 설정하여 허가된 IP 대역에서만 접속하도록 설정할 수 있습니다.
. prometheus.prometheusSpec.serviceMonitorSelectorNilUsesHelmValues: false
다른 헬름 차트에서 정의한 서비스모니터 커스텀 리소스(CR, CustomResource)를 사용할 수 있도록 합니다.
. prometheus.prometheusSpec.retention
메트릭 데이터 보관 기한을 지정합니다. 저는 테스트 환경이라 5일(5d)로 지정하였습니다. 상황에 따라 1개월, 6개월 등으로 변경합니다.
. prometheus.prometheusSpec.retentionSize
스토리지 용량을 지정합니다. PVC 확장이 가능하므로 실제 사용량에 따라 변경할 수 있습니다.
위와 같이 기본 설치 옵션에서 간단한 설정을 변경한 것만으로도 초기 운영 환경에 적용 가능한 모니터링 시스템 구축이 가능합니다. 물론 실제 환경에서는 많은 추가 작업이 필요하지만 초기 시작으로는 아주 훌륭한 시스템 구축이 가능합니다.
그럼 설치를 진행합니다.
(jerry-test:kubecost)kube-prometheus-stack-48.3.1$ k ns monitoring (jerry-test:monitoring)kube-prometheus-stack-48.3.1$ helm install prometheus -f ci/my-values.yaml . NAME: prometheus LAST DEPLOYED: Sat Nov 4 13:59:39 2023 NAMESPACE: monitoring STATUS: deployed REVISION: 1 NOTES: kube-prometheus-stack has been installed. Check its status by running: kubectl --namespace monitoring get pods -l "release=prometheus" Visit https://github.com/prometheus-operator/kube-prometheus for instructions on how to create & configure Alertmanager and Prometheus instances using the Operator.
정상으로 설치가 완료되면 아래의 파드가 실행됩니다.
(jerry-test:monitoring)~$ k get pod NAME READY STATUS RESTARTS AGE alertmanager-prometheus-kube-prometheus-alertmanager-0 2/2 Running 0 16h prometheus-grafana-7cbdbd5c47-4rrw4 3/3 Running 0 16h prometheus-kube-prometheus-operator-795b9759b8-t8pbs 1/1 Running 0 16h prometheus-kube-state-metrics-6df4697c45-n9b67 1/1 Running 0 16h prometheus-prometheus-kube-prometheus-prometheus-0 2/2 Running 0 16h prometheus-prometheus-node-exporter-rnwsz 1/1 Running 1 (16h ago) 16h prometheus-prometheus-node-exporter-w2vpl 1/1 Running 0 16
각 파드에 대하여 알아보겠습니다.
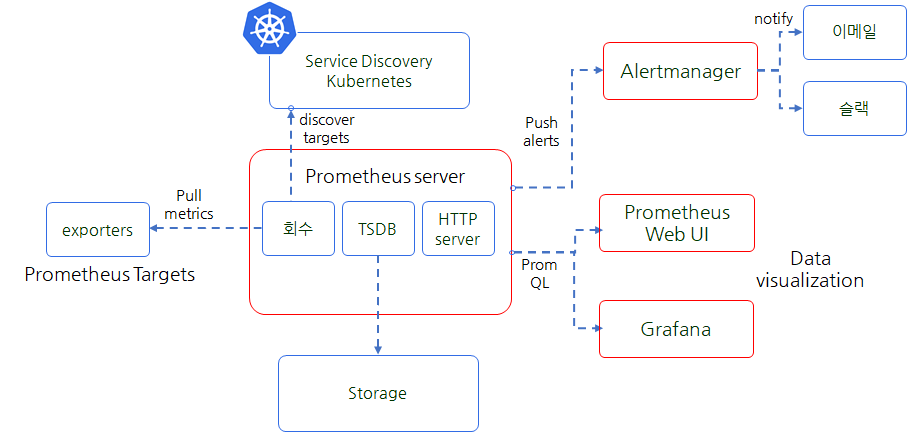
- 얼럿매니저(alertmanager)
프로메테우스는 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성합니다. 해당 메시지는 얼럿매니저로 전달되고 얼럿매니저는 중복 제거, 메시지 그룹화, 억제 등의 사후 처리 작업을 거쳐서 지정된 이메일, 슬랙 등의 경보 전달 채널로 전송합니다. - 그라파나(grafana)
프로메테우스는 메트릭 정보를 저장하는 용도로 사용하며 해당 정보 조회는 프로메테우스에서는 기본적인 그래프 형태만 가능합니다. 사용자는 별도의 시각화 솔루션인 그라파나로 다양한 그래프와 차트를 생성할 수 있습니다. 그라파나는 메트릭 정보를 프로메테우스와 동일하게 PromQL(Prometheus Query Language) 검색 언어로 조회할 수 있습니다. - 프로메테우스 파드(prometheus-0)
프로메테우스 파드는 스테이트풀셋(statefulset)으로 배포됩니다. 모니터링 대상이 되는 파드는 ‘exporter’라는 별도의 사이드카 형식의 컨테이너로 모니터링 대상이 되는 메트릭을 노출합니다. 해당 메트릭을 프로메테우스 파드는 Pull 방식으로 가져와서 내부의 시계열 데이터베이스(TSDB, Time Series DataBase)에 저장합니다. 저장된 정보는 프로메테우스 웹 서버 또는 그라파나를 통하여 그래프 형태로 조회합니다. 시스템 경고(alert) 알람은 얼럿매니저로 전달합니다. - 노드익스포터(node-exporter)
데몬셋으로 설치되어 모니터링 대상이 되는 전체 노드에 자동으로 설치됩니다. 노드익스포터는 물리 노드에 대한 자원 사용량(네트워크, 스토리지 등 전체) 정보를 메트릭 형태로 변경하여 노출(expose)합니다.
위 필수 구성 요소 이 외 프로메테우스 헬름 차트는 아래의 파드를 추가로 설치합니다.
- 프로메테우스 오퍼레이터(prometheus-operator)
시스템 경고 메시지 정책(prometheus rule), 애플리케이션 모니터링 대상 추가(ServiceMonitor) 등의 작업을 편리하게 할 수 있도록 Custom Resource를 지원합니다. - kube-state-metrics
이름으로 알 수 있듯이 쿠버네티스의 상태(kube-state)를 메트릭으로 변환하는 파드입니다. 쿠버네티스 API 서버와 통신하여 각 오브젝트의 상태를 메트릭 형태로 변환하여 프로메테우스가 수집할 수 있도록 합니다. 컨트롤 플레인 노드 애플리케이션 상태, 쿠버네티스 리소스 리스트 현황 등 클러스터 전반에 관한 상황을 확인할 수 있습니다. 기존 VM 환경과 다른 지점입니다.
알아두셔야할 것이 프로메테우스는 2가지 추가 CR(Custom Resource)를 사용합니다. 애플리케이션 모니터링 대상은 ServiceMonitor, 알람 경고 설정은 PrometheusRules 입니다.
(jerry-test:default)~$ k get servicemonitors.monitoring.coreos.com -A NAMESPACE NAME AGE monitoring prometheus-grafana 4d11h monitoring prometheus-kube-prometheus-alertmanager 4d11h monitoring prometheus-kube-prometheus-apiserver 4d11h (jerry-test:default)~$ k get prometheusrules.monitoring.coreos.com -n monitoring NAME AGE prometheus-kube-prometheus-alertmanager.rules 4d11h prometheus-kube-prometheus-config-reloaders 4d11h prometheus-kube-prometheus-etcd 4d11h (생략)
ServiceMonitor는 Prometheus Operator와 함께 사용되는 커스텀 리소스입니다. 이 리소스는 Prometheus가 쿠버네티스 서비스를 어떻게 발견하고 스크레이핑해야 하는지를 정의합니다. ServiceMonitor는 특정 서비스의 메트릭을 수집하는 방법과 주기, 포트, 경로 등을 지정합니다. Prometheus Operator는 ServiceMonitor 리소스를 사용하여 자동으로 Prometheus의 스크레이핑 설정을 구성하고, 지정된 서비스에서 메트릭을 수집합니다. 이를 통해 사용자는 수동으로 Prometheus의 설정을 조정할 필요 없이, 쿠버네티스 내에서 메트릭 수집을 효율적으로 관리할 수 있습니다.
향후 운영 시 애플리케이션에 따라 모니터링 설정을 추가하는 경우 위 2가지 리소스 변경 사항을 확인하면 됩니다.
이러한 전체 구성요소를 간단히 그림으로 표현하면 아래와 같습니다.
3. Node-Exporter 아키텍처 확인
그럼 Prometheus가 어떻게 Pull 방식으로 각 에이전트의 메트릭 정보를 가져오는지 Node-Exporter 구성을 확인하여 알아보겠습니다. port-forwarding을 이용하여 node-exporter 파드에 접속합니다.
(jerry-test:monitoring)~$ k port-forward svc/prometheus-prometheus-node-exporter 9100:9100 Forwarding from 127.0.0.1:9100 -> 9100 Forwarding from [::1]:9100 -> 9100
아래 스크린 캡쳐에서 확인할 수 있듯이 node-exporter의 ‘/metrics’ 디렉토리에 접속하면 모니터링 관련 메트릭을 확인할 수 있습니다. 아래는 필자가 ‘cpu’로 검색한 내용으로 CPU 사용률 관련 메트릭이 조회되는 것을 확인할 수 있습니다.
이렇게 Node-Exporter가 제공하는 메트릭을 Prometheus가 Pull 방식으로 가져와서 Prometheus 자체 시계열 스토리지에 관련 정보를 저장하는 구조로 동작합니다.
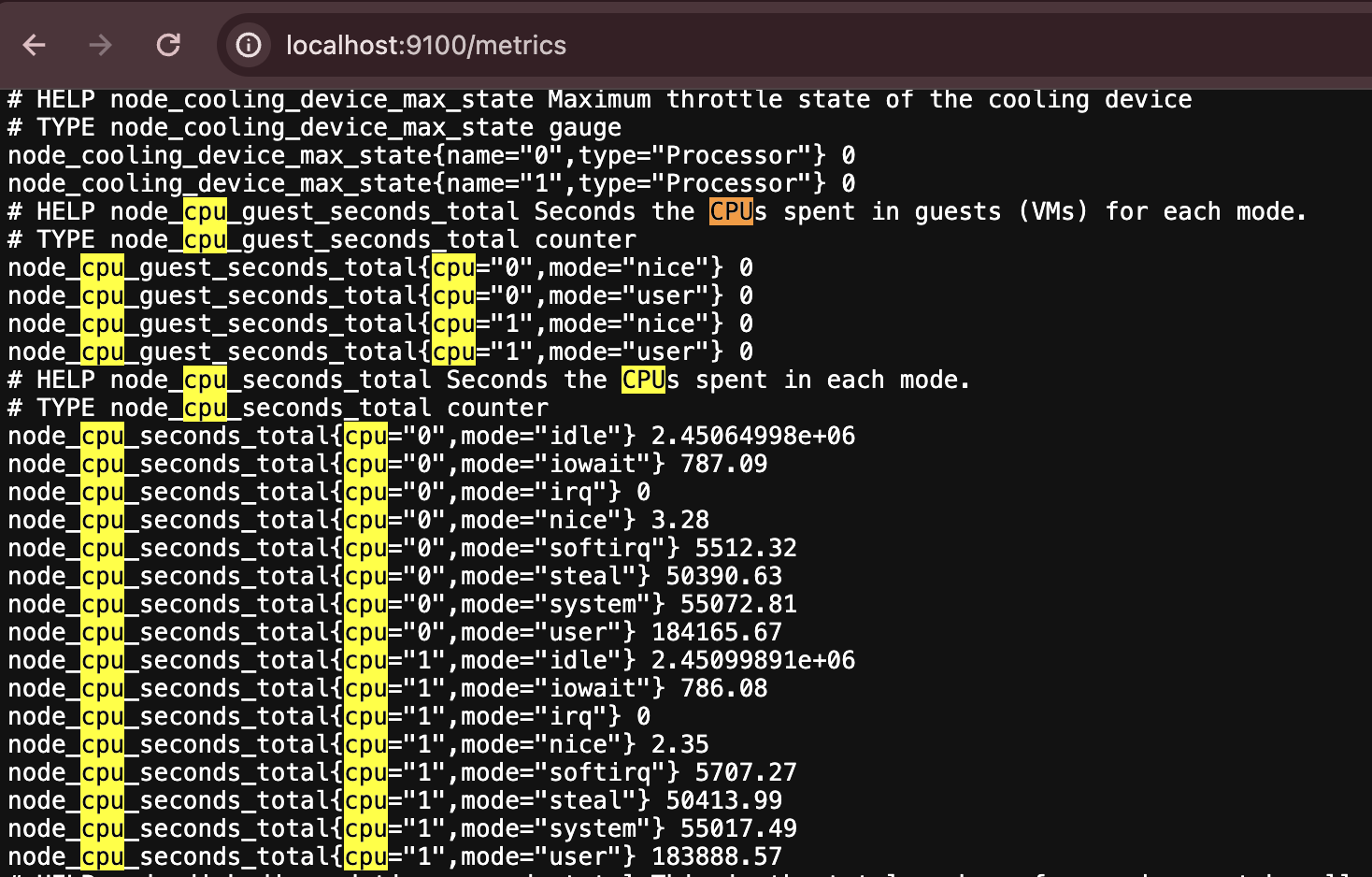
서비스 운영 중 특정 메트릭 존재 여부 확인이 필요하면 위와 같이 해당 메트릭을 제공하는 애플리케이션의 Exporter에서 해당 메트릭이 존재하는지 직접 확인할 수 있습니다.
이제 동일하게 port-forward를 이용하여 Prometheus UI에 접속하겠습니다.
(jerry-test:monitoring)~$ k port-forward svc/prometheus-kube-prometheus-prometheus 9090:9090 Forwarding from 127.0.0.1:9090 -> 9090 Forwarding from [::1]:9090 -> 9090
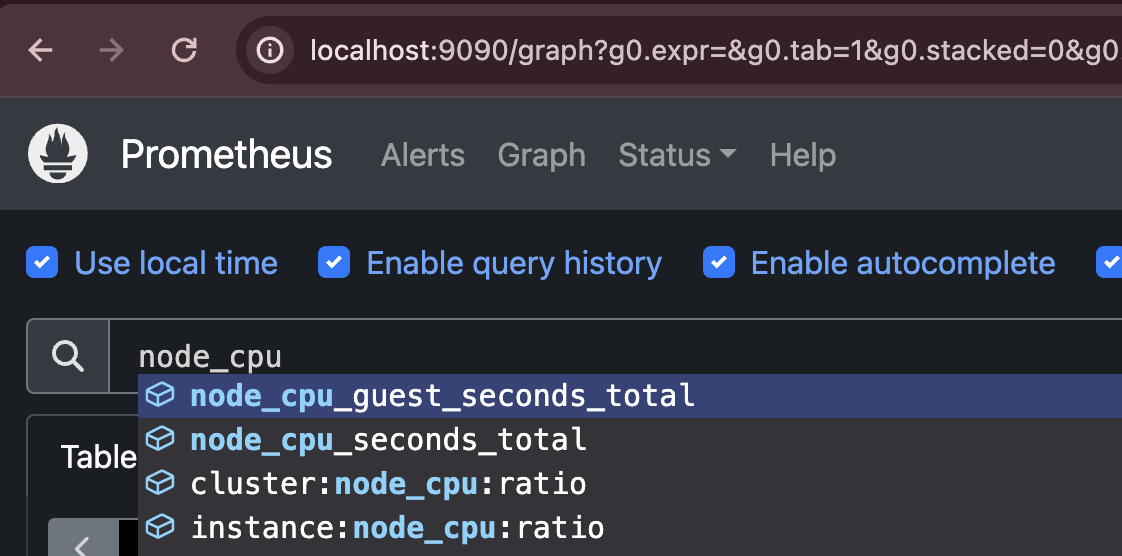
‘Graph’ 메뉴에 node_cpu 관련 메트릭을 조회하면 아래와 같이 정상으로 조회됩니다. node-exporter가 제공하는 메트릭 관련 정보를 정상으로 불러오고 내부에 저장하여 해당 메트릭을 조회할 수 있습니다.
간단히 도식화하면 아래와 같습니다.
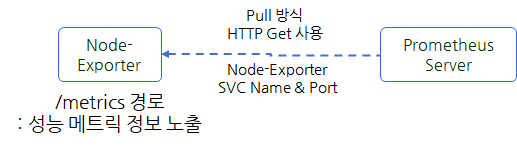
<그림 프로메테우스 서버 메트릭 정보 수집 방법>
4. 프로메테우스 어드민 페이지
이제 프로메테우스 어드민 페이지를 알아보겠습니다. 프로메테우스에 접속하면 아래와 같은 상단 메뉴를 확인할 수 있습니다.

간략한 주요 메뉴 설명입니다.
- 경고(Alerts)
사전에 정의한 시스템 경고 정책(Prometheus Rules)에 대한 상황을 나타냅니다. 시스템 알람 메시지를 확인하는 경우 해당 페이지를 이용합니다. 알람에 대한 자세한 설정은 이어지는 장에서 다룹니다. - 그래프(Graph)
프로메테우스 자체 검색 언어 PromQL을 이용하여 메트릭 정보를 그래프로 조회할 수 있습니다. 프로메테우스는 단순한 그래프만 지원하고 다양한 시각화 효과는 시각화 전용 솔루션, 그라파나를 사용합니다. 단순히 메트릭 확인 용도로만 사용합니다. - 상태(Status)
경고 메시지 정책(Rules), 모니터링 대상(Targets) 등 다양한 프로메테우스 설정 내역을 확인할 수 있습니다. 주요 메뉴에 대한 설명은 아래에서 좀 더 자세히 다룹니다.
DevOps, 인프라 관리자로 눈여겨 보아야 하는 메뉴는 주로 3번 상태(Status) 입니다. 상세 사례로 ‘Status’ – ‘Targets’ 메뉴를 선택합니다.
<Status – Target 메뉴>
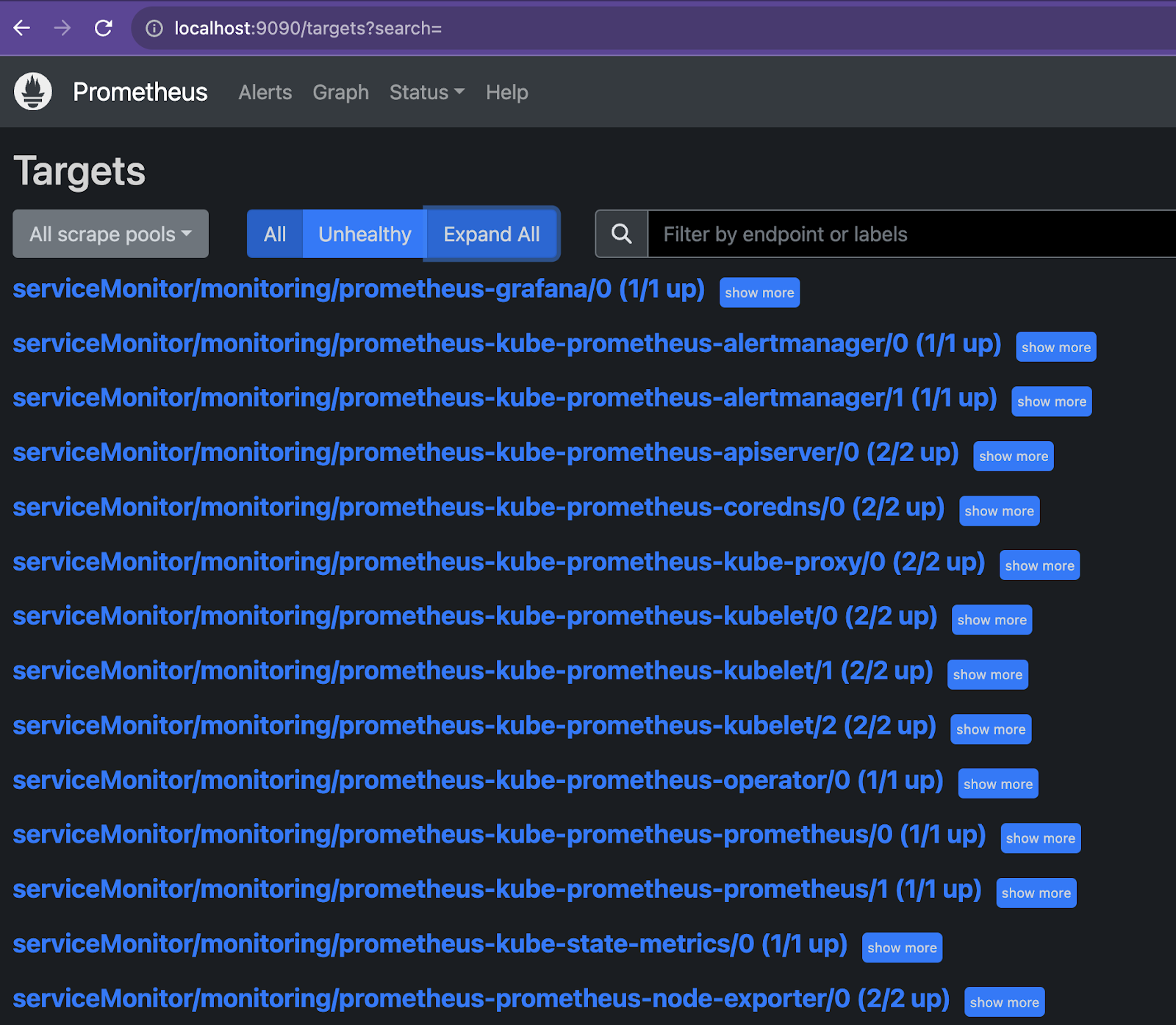
<모니터링 대상(Target) 리스트>
앞에서 조회한 ‘ServiceMonitor’ 커스텀 리소스 목록을 확인할 수 있습니다.
(jerry-test:default)~$ k get servicemonitors.monitoring.coreos.com -A NAMESPACE NAME AGE monitoring prometheus-grafana 4d11h
해당 메트릭이 정상으로 모니터링 되면 위와 같이 ‘up’ 상태이고 문제가 있으면 ‘down’으로 표시됩니다. 특정 애플리케이션의 모니터링 쿼리(PromQL)가 실행되지 않으면 가장 먼저 확인해야할 부분 중 하나입니다.
다음으로 ‘Status’ – ‘Command-Line Flags’를 확인하면 헬름 설치 시 등록한 Values 설정을 확인할 수 있습니다.
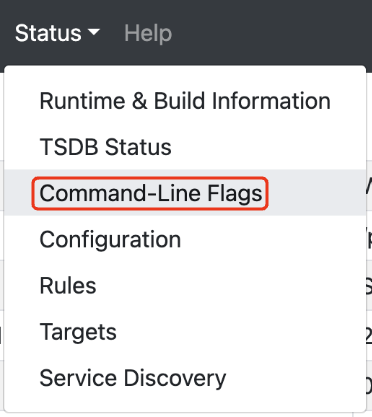

헬름 Values 파일에서 설정한 여러 설정등이 실제 반영한 내역을 확인할 수 있습니다. 저희는 초기 설정으로 간단히 스토리지 용량 ‘10GiB’, 스토리지 보관 기한 ‘5d’ 등을 설정하였는데, 해당 내역이 실제 반영된 내역을 확인할 수 있습니다.
기타 프로메테우스 운영 관련 버전, scrape_interval(모니터링 주기), scrape_timeout 등 여러 설정 정보가 ‘Runtime & Build Information’, ‘Configuration’ 메뉴에서 확인할 수 있습니다. 필요에 따라 확인 후 수정하면 됩니다.
그럼 실 운영 환경에서 애플리케이션 모니터링을 추가하는 사례를 알아보겠습니다. 특정 애플리케이션을 추가하여 해당 애플리케이션의 상태를 확인하기 위해서 모니터링을 등록하는 것은 운영 단계에서 자주 발생하는 업무입니다. 이러한 업무가 Prometheus에서는 Exporter 리소스를 이용하여 매우 효과적으로 처리됩니다.
대부분의 애플리케이션은 헬름 차트에 모니터링 관련 Exporter 부분을 포함합니다. 해당 옵션을 ‘Enable’하여 비교적 간단하게 프로메테우스에 모니터링 에이전트로 등록할 수 있습니다. 프로메테우스가 모니터링 솔루션의 표준으로 사용되는 것의 강력한 장점입니다.
그럼 앞에서 설치한 Redis 사례로 확인해 보겠습니다. Redis 헬름 차트의 Values.yaml 파일입니다. 해당 파일은 깃허브에서 확인할 수 있습니다.
architecture: replication
auth:
enabled: false
master:
count: 1
replica:
replicaCount: 2
sentinel:
enabled: false
metrics:
enabled: true
serviceMonitor:
enabled: true ## serviceMonitor - Exporter 등록
prometheusRule:
enabled: true ## 알람 Rule 등록
sysctl:
enabled: true
. metrics.enabled
프로메테우스가 모니터링 가능하도록 Redis Exporter 설정을 등록합니다. Prometheus는 Exporter를 사용하여 메트릭을 모니터링합니다. Exporter는 시스템이나 서비스의 메트릭을 수집하여 Prometheus가 이해할 수 있는 형식으로 변환하는 역할을 하는 도구입니다. 이를 통해 다양한 소스에서 수집된 메트릭을 통합적으로 모니터링할 수 있습니다. 다양한 시스템과 애플리케이션에서 생성된 메트릭을 Prometheus의 표준 형식으로 메트릭을 변환합니다. 이를 Exporter는 수집된 메트릭을 Prometheus가 스크레이핑할 수 있는 HTTP 엔드포인트에 노출합니다.
. metrics.serviceMonitor.enabled
‘serviceMonitor’ 커스텀 리소스에 등록하여 프로메테우스 리소스 재시작없이 모니터링 대상으로 등록합니다.
. metrics.prometheusRule.enabled
알람 Rule로 등록합니다.
모니터링 설정을 포함하여 Redis 헬름 차트를 배포합니다. 설치 후 파드의 수량을 확인하면 아래와 같이 ‘2’개입니다.
(jerry-test:redis)~$ k get pod NAME READY STATUS RESTARTS AGE redis-master-0 2/2 Running 0 4d11h redis-replicas-0 2/2 Running 0 4d11h redis-replicas-1 2/2 Running 0 4d11h
상세 설정을 확인하면 모니터링 관련 Exporter 파드가 Sidecar 형식으로 추가 실행 중인걸 알 수 있습니다.
(jerry-test:redis)~$ k describe pod redis-master-0
(중략)
Containers:
redis:
Container ID: containerd://b41aedc6ab5a8d72b7afec0691c3cf5cbf7115a26e4cfad40f46fe3aed5d307d
Image: docker.io/bitnami/redis:7.0.9-debian-11-r1
Image ID: docker.io/bitnami/redis@sha256:57e071d75ab5eff3dcafd53107f256e1a2b41eeb52eddc73395487ebf83fa257
(중랽)
metrics:
Container ID: containerd://3886b68cb873cc2b912f2f92001647193cba2ce2a3d1d05bfcb5a459f66f9075
Image: docker.io/bitnami/redis-exporter:1.47.0-debian-11-r1
Image ID: docker.io/bitnami/redis-exporter@sha256:dd009d59117afcefc277f66a5f189ab9ec6e7b490245241b7b6efc9b5a46279c
Port: 9121/TCP
‘redis’ 파드 이 외 ‘metrics’ 파드가 ‘redis-exporter’로 실행 중입니다. 이렇게 서로 이미지를 분리하여 모니터링 설정을 추가하는 경우에도 기존 이미지 변경없이(불변 이미지 원칙) 새로운 exporter 이미지를 추가하는 형태로 운영됩니다. Exporter 사이드카 이미지를 이용하여 프로메테우스에 에이전트로 등록됩니다.
해당 설정이 완료되면 Redis와 관련된 ‘ServiceMonitor’, ‘PrometheusRules’ 리소스를 확인할 수 있습니다.
(jerry-test:redis)~$ k get servicemonitors.monitoring.coreos.com kNAME AGE redis 4d11h (jerry-test:redis)~$ k get prometheusrules.monitoring.coreos.com NAME AGE redis 4d11h
이제 Redis 애플리케이션이 모니터링 대상으로 정상 등록이 완료되어 다음 장에서 살펴볼 대시보드에 해당 메트릭을 이용하여 Redis 애플리케이션 모니터링을 완성할 수 있습니다.
이처럼 헬름 설정에 모니터링 옵션을 추가하는 것만으로 비교적 간단하게 애플리케이션 모니터링 설정을 진행할 수 있습니다.
이상으로 이번 장에서 Prometheus 핵심을 간략하게 알아보았습니다. Prometheus의 강력한 모니터링 기능과 확장성은 현대 IT 인프라 관리의 필수적인 부분입니다. 단순히 데이터를 수집하고 표시하는 것을 넘어서, 시스템의 성능을 최적화하고 잠재적인 문제를 사전에 예방하는 데 큰 역할을 합니다. 우리가 Prometheus를 통해 얻는 통찰력은 IT 환경이 직면한 끊임없는 도전을 극복하는 데 있어 중요한 자산이 됩니다.
해당 기술 블로그에 질문이 있으시면 언제든지 문의해 주세요. 직접 답변해 드립니다.
k8sqna@jennifersoft.com
1. CNCF 2번째 졸업 프로젝트 : https://www.cncf.io/announcements/2018/08/09/prometheus-graduates/
2. SoundCloud에서 시작된 Prometheus 프로젝트 : https://prometheus.io/docs/introduction/overview/
3. 로그, 트레이싱은 이어지는 장에서 다루겠습니다.
4. Kube-Prometheus-Stack 헬름 차트 : https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack
5. 얼럿매니저 역할, https://prometheus.io/docs/alerting/latest/alertmanager/
6. kube-state-metrics, https://github.com/kubernetes/kube-state-metrics
