스택트레이스 샘플링을 이용한 성능 분석

개발자 Y씨가 다니는 J사는 오래된 버전의 설치형 제품 Jira 를 사용하고 있습니다.
IDC 어딘가에 설치되어 있고 장비가 노후된 것을 익히 알고 있었지만 하드웨어 단위로 할당된 라이센스 정책 때문에 업그레이드도 새로운 곳에 설치하기도 어려운 상황입니다.
간혹 너무나도 느려지는 응답속도에 마음이 답답한 Y씨 (도대체 왜 느린거야!) 😤
회사에서 개발하고 있는 APM 을 설치하여 메소드 프로파일을 시도하려 하지만 이내 곧 좌절하고 맙니다.
“어떤 패키지를 설정해야 하지?”
“일단 모니터링 해보자!”
Y씨는 설치한 APM의 핵심 기능인 X-View 차트에서 Y 축의 상단에 위치한 트랜잭션을 확인할 수 있었습니다. (오오..)
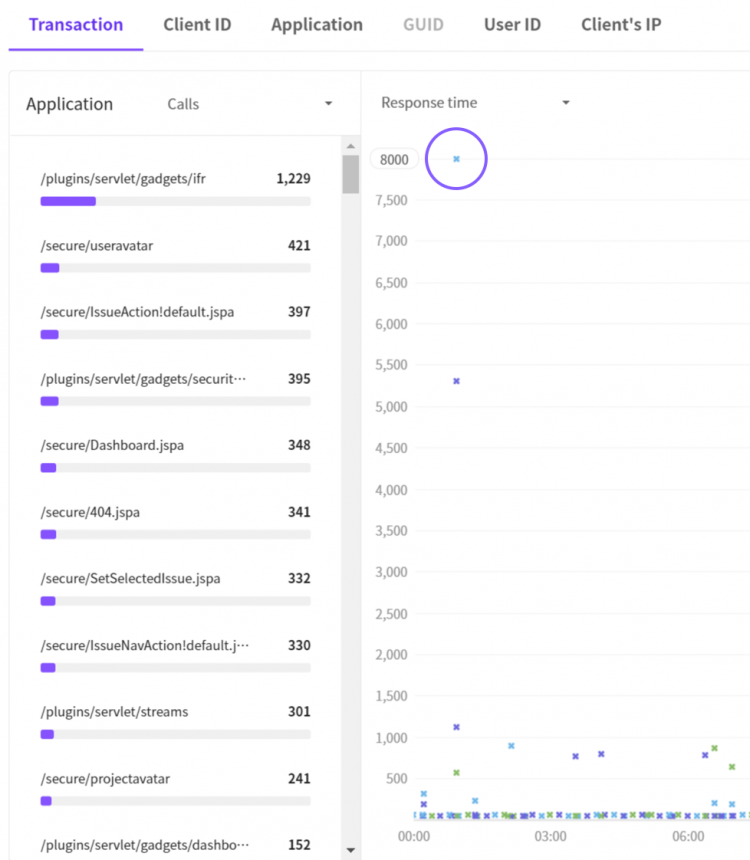
한껏 기대에 부푼 마음으로 차트의 천장을 뚫을것만 같은 점을 드래그 해봅니다.

“트랜잭션이 끝날 무렵 12초 이상 시간이 걸리고 있네.. 원인이 뭘까?” 🧐
지연되는 영역이 SQL, HTTP 호출과 같은 전통적인 병목 지점이 아니었기에 마음만 답답해집니다. Jira 라는 제품이 아틀라시안이라는 회사에서 개발된 것을 알고 있으니 com.atlassian 패키지를 대상으로 프로파일 설정을 해봅니다.
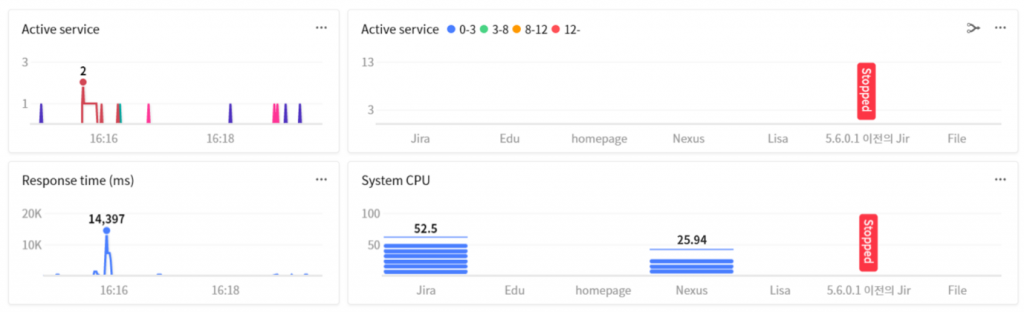
😱 헉.. 설정을 한 순간 시스템 CPU 사용률이 52% 를 넘고 있습니다!
조마조마한 마음을 가라 앉히고 잠시 후 X-View 차트를 드래그 해봅니다.
Y씨 과연 원인을 파악할 수 있을까요?
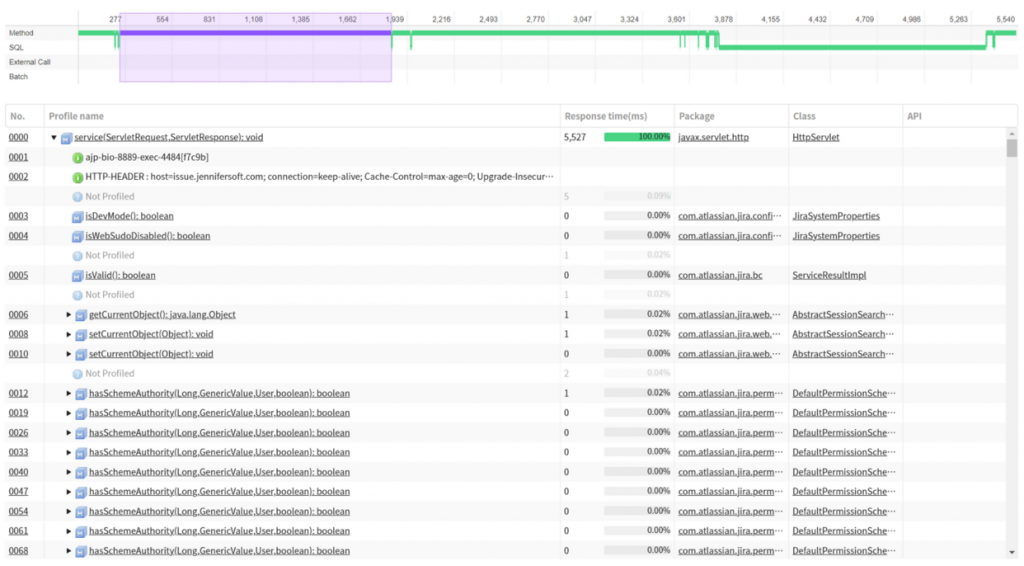
아.. 무수한 메소드들이 프로파일링 되었지만 안타깝게도 대부분 0ms, 1ms 소요된 메소드들이 보입니다. 거기에 X-View 차트를 보니 서비스의 응답시간이 많이 느려지고 있네요.
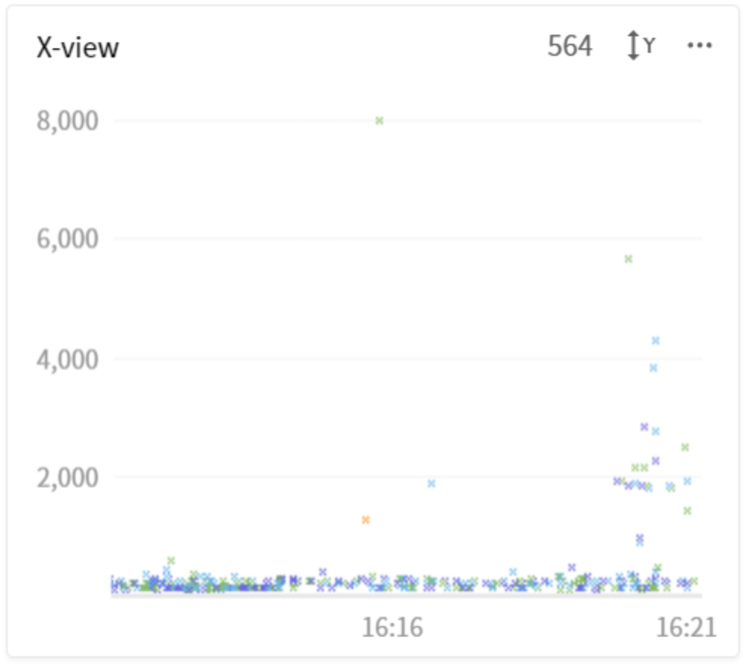
Y씨는 이제 부장님께 혼이 날지도 모르겠습니다. (힘내요!)🥺
그렇다면 프로파일링을 시도한 것은 과연 잘못된 방법일까요?
지연의 원인이 설정한 패키지 내의 어떤 클래스의 메소드였다면 원인을 찾을 수 있을지도 모릅니다.
하지만 현대의 애플리케이션은 사용자가 개발한 특정 메소드의 성능이 매우 나빠 응답시간에 큰 영향을 주지 않습니다.
대부분의 환경에서는 이미 잘 준비된 프레임워크를 이용하여 개발하기 때문입니다.
실제로 com.atlassian 패키지를 프로파일링 하면 눈에 띄는 프로파일 정보를 확인할 수 없습니다.
내부적으로 캐시들을 준비해 놓았을 것이고 이것들은 성능 문제로 이어질 가능성이 낮습니다.
오래 걸린 SQL 혹은 HTTP 호출이라도 있다면 원격지의 대상을 상대로 튜닝을 시도를 해 볼 수 있겠으나 관련 정보가 없다면 원인 파악은 더욱 어려워집니다.
로딩된 클래스에 해당하는 패키지를 전부 설정한다면(!!) 찾을 수는 있겠죠.
하지만 애플리케이션에 가해지는 추가적인 부하와 데이터 양으로 상당한 비용을 지불해야 할 것입니다.
🤔 그렇다면 이런 상황에서는 어떻게 분석을 해야 할까요?
성능 분석 방법은 크게 프로파일링과 샘플링 두가지 분류의 방법이 있습니다.
1. 프로파일링
실행되는 각 메소드로부터 성능 정보를 수집한 뒤 오랜 시간 실행된 메소드를 찾아 개선

Transaction1, Transaction2 의 가장 느린 메소드는 각각 Method2, Method 4 입니다.
2. 샘플링
애플리케이션의 메서드 호출 여부를 주기적으로 수집하여 호출 빈도가 높은 메소드를 찾아 개선
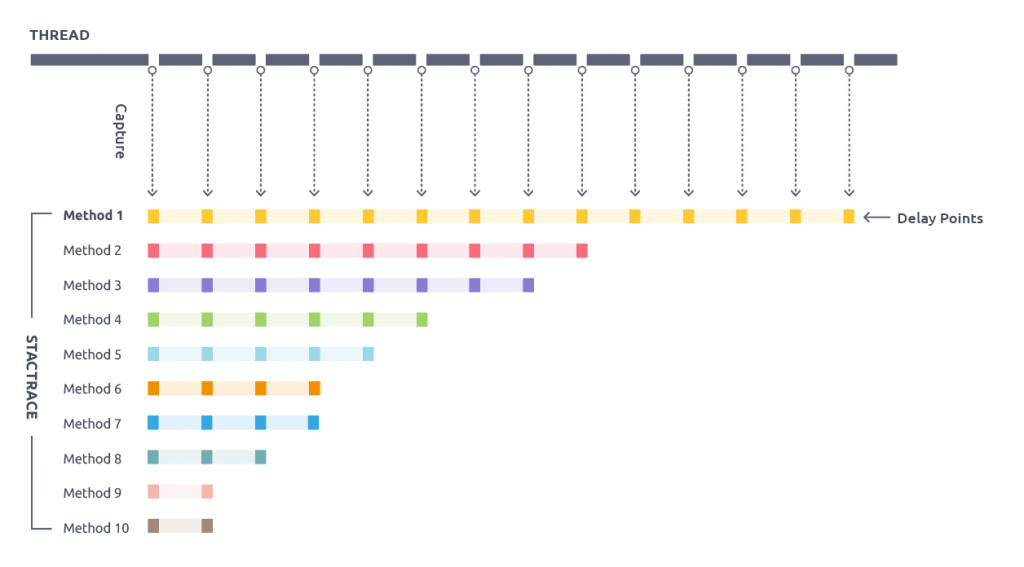
그림에서는 Method1이 지연의 원인이라 볼 수 있습니다.
프로파일링은 전통적인 성능 분석 방법이기에 오랜 역사를 자랑합니다.
그만큼 대다수의 모니터링 제품이 프로파일링 중점의 기능을 기본적으로 제공합니다.
하지만 완벽할 것만 같은 이 프로파일링에도 다음과 같은 한계가 존재합니다.
- 모니터링 할 대상 메소드를 사용자가 알아야 한다. (개발자라면 그나마 나을지도..)
- 높은 트래픽을 받는 운영 환경의 애플리케이션에 사용시 성능에 영향을 준다. (실수로 클래스가많은 패키지라도 설정하는 날에는..?)
하지만 진정한 성능 개선을 위한 트래픽은 운영 환경에서만 발생하는 법.
어떤 상황에서라도 모니터링 할 수 있는 방법이 있다면 프로파일링의 한계를 보완할 수 있겠죠?
그 방법 중 하나가 앞서 소개한 샘플링 입니다.
개별 메소드를 직접 추적하지 않고 메소드의 호출 근원지인 각 스레드로부터 스택트레이스를 주기적으로 수집하여 등장 빈도수를 기반으로 병목지점을 찾는 방법입니다.
(스택트레이스를 100ms 주가로 3번 수집했을때 a 라는 메소드가 3번 모두 등장했다면 a 메소드는 300ms 동안 실행되었다고 간주하는 것입니다.)
프로파일링 방법에 비하여 정확도는 다소 떨어지지만 상대적으로 성능에 작은 영향을 미치며 데이터를 수집할 수 있습니다.
처리 지연을 유발하는 주 원인으로는 어떤 것들이 있을까요?
- CPU 자원을 많이 소모하는 메소드
- I/O 를 동기로 처리하는 메소드
- 크기가 큰 컬렉션 객체를 이터레이션 하는 메소드
- 불필요하게 스레드 동기화 처리된 메소드
스택트레이스를 이용한 샘플링 방법을 이용하면 별다른 설정없이 위 항목에 해당하는 메소드를 쉽게 찾을 수 있습니다. CPU를 많이 소모하든 I/O 처리를 하든 결국 오랜시간 실행되는 메소드는 스택트레이스에 반복적으로 나타나기 때문입니다. 물론 샘플링 역시 새로운 분석 방법이 아니기 때문에 기존에도 사용하기 좋은 여러가지 도구들이 존재합니다.
저는 VisualVM 을 주로 사용하는데 스레드별 스택트레이스를 주기적으로 수집하여 호출 빈도를 보기 좋게 표시하여 병목지점을 쉽게 찾을 수 있습니다.
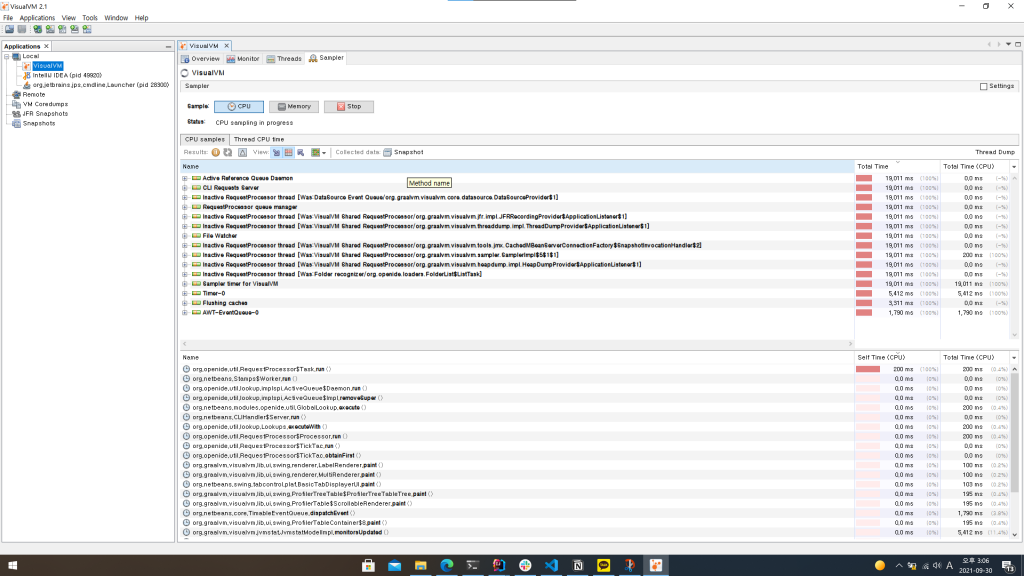
성능에 미치는 영향이 매우 적기 때문에 트래픽이 높은 운영 환경에서도 부담없이 이용할 수 있습니다. 실제로 제가 담당하고 있는 APM 수집 서버의 성능 개선에도 여러 차례 유용하게 쓰였습니다.
그렇게 시간이 흘러흘러.. 문득 이런 생각이 들었습니다.
🧐 “이런 툴은 고객사 내에서 쉽게 사용을 할 수 없는데.. (보안등 여러 이유가 있다고 합니다.)
샘플링 분석 방법으로 얻은 이 효과를 우리 제품의 사용자들도 느끼면 좋겠다.”
🤔 “하.. 정말 좋은데 어떻게 설명할 방법이 없네..”
😀 “에잇. 그냥 우리 제품에서 이런 방법을 제공하면 안될까?!”
트랜잭션에서 수집된
개별 스택트레이스 확인하기
제니퍼 역시 앞서 이야기 한 프로파일링의 한계로부터 자유롭지 않습니다.
실시간으로 원하는 메소드를 손쉽게 프로파일링 할 수 있지만 결국 어디를 봐야할지 알아야 하기 때문입니다. 물론 이를 보완하기 위한 여러가지 방법이 준비되어 있습니다. 주로 실시간으로 스택트레이스 정보를 얻은 뒤 프로파일링 할 대상을 찾게 됩니다.
- 소켓 모니터링 기능을 이용하여 특정 포트의 스택트레이스로부터 프로파일 대상 선별
- 스레드 모니터링 기능을 이용하여 특정 스레드의 스택트레이스로부터 프로파일 대상 선별
- 다이나믹 스택트레이스 기능을 이용하여 특정 클래스 혹은 메서드를 호출한 지점까지의 스택트레이스를 얻은 뒤 프로파일 대상 선별
위 방법을 이용해도 찾지 못한 호출 구간은 X-View 상세보기 팝업에서 Not Profiled 영역으로 표시됩니다.
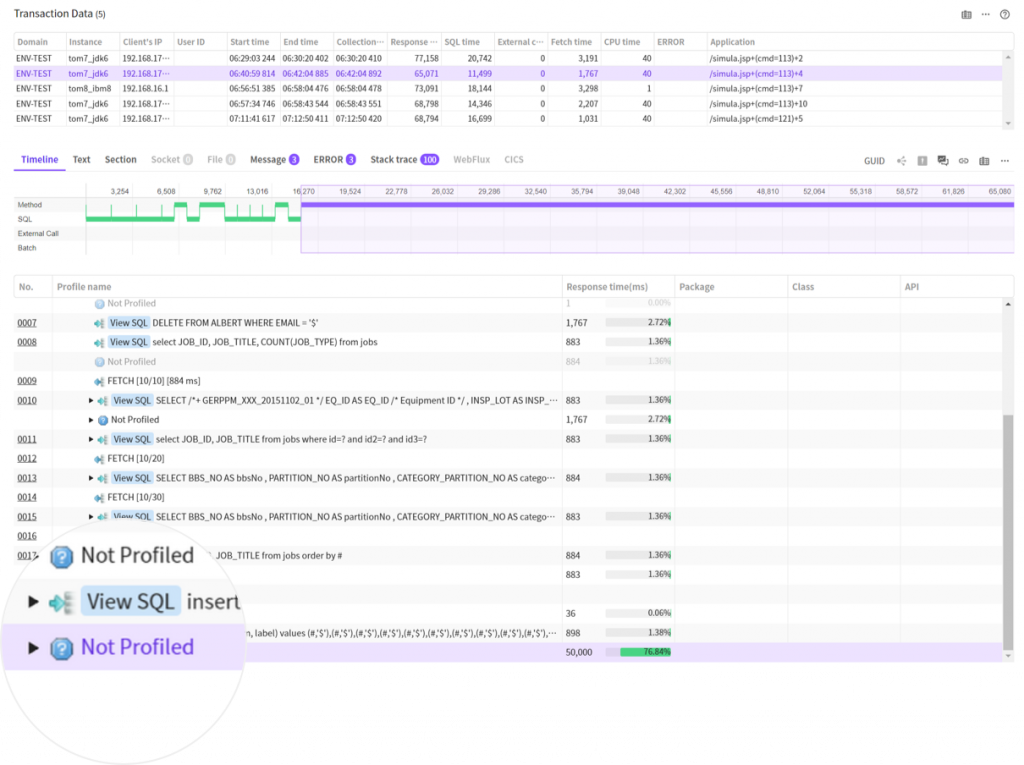
조금이라도 시간이 길게 소요된 Not Profiled 영역이 있다면 모니터링을 하는 입장에서 당연히 해당 구간에서 있었던 일을 확인하고 싶을 것이라고 생각합니다.
그래서 트랜잭션별 스택트레이스를 수집하여 수집 시간의 역순으로 나열해서 보여주기로 했습니다.
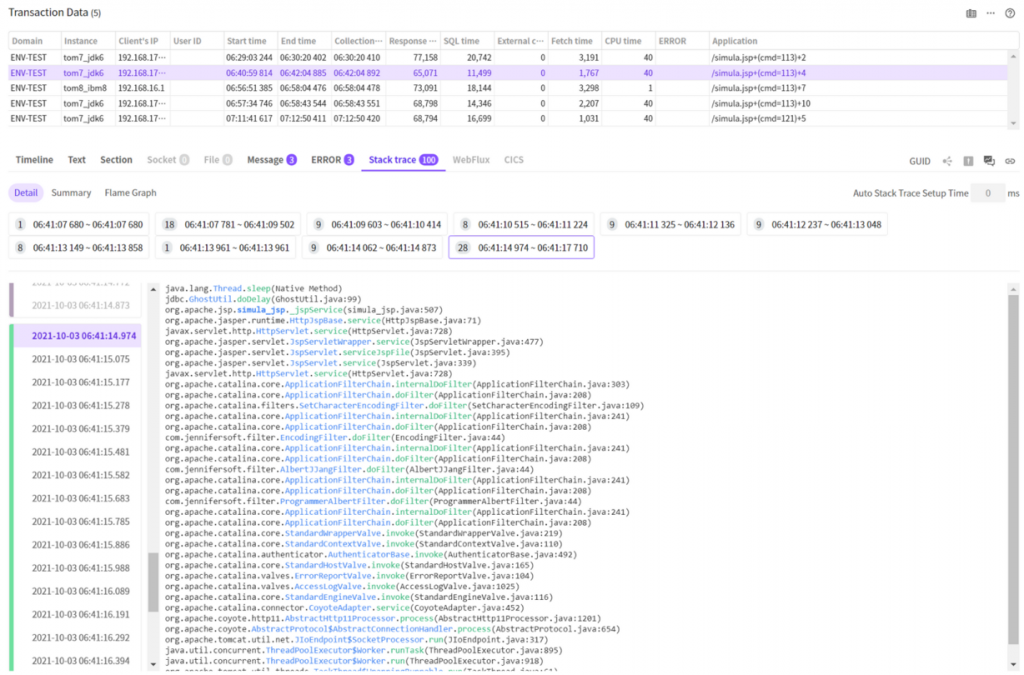
시간 순서대로 나열된 스택들을 하나하나 살펴보면 트랜잭션 내에서 어떤 동작이 있었는지 확인 가능합니다.
위 스크린샷의 트랜잭션은 대부분 Thread.sleep() 메소드를 지속적으로 호출하고 있네요.
개발자가 데모환경 구성을 위해 인위적으로 넣은 동작으로 추측해 볼 수 있습니다.
jsp 의 컴파일 된 클래스의 메소드를 프로파일링 하면 jspService 메서드가 오랜 시간 소요되었다는 것을 확인할 수 있을뿐 근본적인 원인은 실제 코드를 확인하고 나서야 파악할 수 있었을 것입니다.
트랜잭션에서 수집된
여러개의 스택트레이스 시각화
앞서 예로 든 트랜잭션은 비교적 간단한 내용을 수행하기에 목록으로 나열된 스택트레이스만으로도 대략적인 원인을 파악할 수 있었습니다.
그러나 만약 오랜 시간동안 실행된 트랜잭션에서 여러 종류의 스택트레이스가 100개 가량 수집되었을 경우 많은 개별 스택트레이스를 하나하나 다 확인해야만 하는 불편함이 있습니다.
제니퍼에서는 이러한 상황에서 조금 더 분석을 쉽게 할 수 있도록 두가지 조회 방법을 제공합니다.
요약보기
요약보기는 각각의 메소드 호출 관계를 분석, 요약하여 트리 구조로 표현합니다. 트리로 표시된 각각의 네모 막대는 스택트레이스 내의 메소드를 나타내며 다음과 같은 3개의 정보를 갖고 있습니다.
1. 응답시간
응답시간은 스택트레이스 내에서 한 번이라도 등장한 경우 측정되는 수치입니다.
등장 횟수 x 스택트레이스의 측정 주기로 계산되며 응답시간이 큰 메소드는 시스템 성능의 병목지점의 진입점으로 판단할 수 있습니다.
2. Self 시간
Self 시간은 메소드가 스택트레이스에서 가장 상단에 위치한 경우 측정되는 수치입니다. 즉, 현재 실행중인 메소드이며 이 수치가 크다면 시스템의 병목지점일 가능성이 높습니다. I/O 를 발생시키는 메소드가 주를 이루며 경우에 따라 CPU 를 많이 소모하는 메소드일 수 있습니다.
3. Retained Self 시간
Reatined Self 시간은 하나의 메소드가 호출한 다른 메소드가 가진 Self 시간의 합입니다.
이 수치가 크면 이 메소드가 호출한 어떤 메소드가 스레드에서 실행중이었던 것으로 간주할 수 있습니다. Self 시간을 갖는 메소드의 진입점을 찾는 목적으로 쓰입니다.
먼저 Retained Self 시간이 큰 노드(파란색)를 중점으로 찾고 그 하위의 Self 시간이 큰 노드(노란색)을 찾으면 실행중이었던 메소드를 쉽게 찾을 수 있습니다.
Flame Chart
Brandon Gregg 에 의해 제안된 차트를 이용한 시각화 방법입니다.
하나의 세로 줄기는 한 종류의 스택트레이스 입니다. 하나의 노드 위에 여러개의 노드가 있을 경우 그 시점에서 호출이 분기 되었음을 나타냅니다.
Flame Chart 는 다음과 같은 특징을 갖고 있습니다.
- 각 색상은 동일한 패키지의 메소드임을 나타냄
- 각 사각형의 넓이는 수집 횟수
- 차트의 최하단에 표시된 메소드는 스택트레이스의 시작지점
- 차트의 최상단에 표시된 메소드는 현재 실행중인 메소드
위와 같은 특성에 기반하여 차트에서 가장 넓은 부분을 찾으면 조회 기간내에 가장 많이 호출된 메소드를 쉽게 찾으르 수 있습니다. 찾은 메소드는 그 시간대의 특정 현상(CPU 소모, 응답시간 지연)의 주요 원인일 가능성이 매우 높습니다.
활용사례
이제 처음에 소개했던 Y씨의 상황을 제니퍼의 개선된 스택트레이스 기능을 이용해 분석해보겠습니다.
우선 느린 트랜잭션의 상세 정보를 XView 팝업에서 확인해 봅시다.
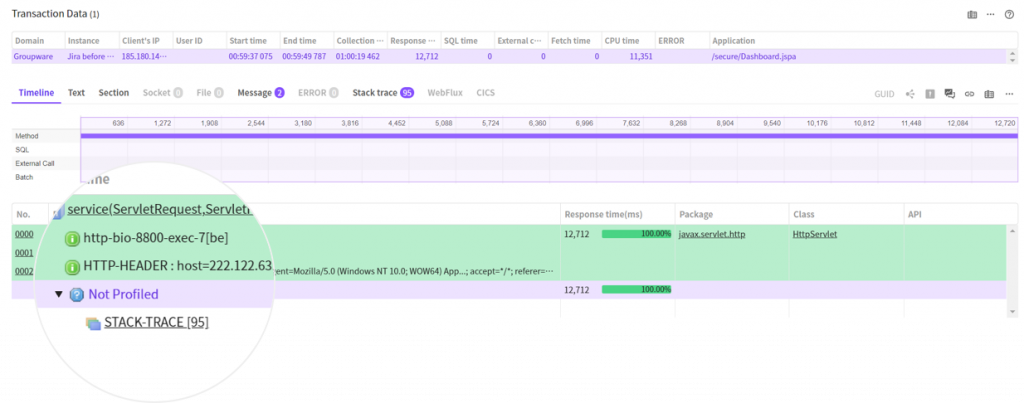
Not Profiled 노드가 대부분의 처리 시간을 포함하고 있네요.
Not Profiled 노드에 STACK-TRACE 라는 하위 노드가 있는 것을 확인할 수 있습니다.
이것은 모든 프로파일과 시간 정보를 기반으로 스택트레이스의 수집 위치를 표시한 것입니다.
위 첨부된 사진의 경우 Not Profiled 구간에서 95개의 스택 트레이스가 수집 되었음을 의미합니다.
이제 STACK-TRACE 노드를 클릭하면 스택트레이스 탭으로 이동하여 매칭되는 스택 그룹이 자동으로 선택 됩니다.
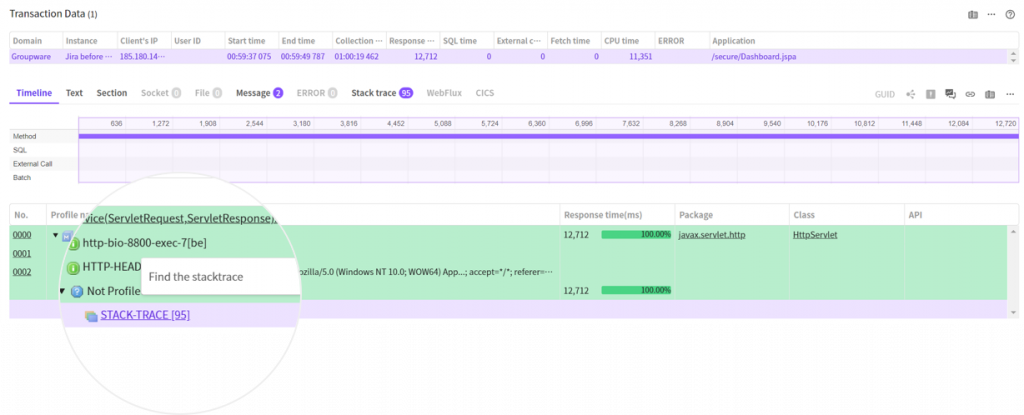
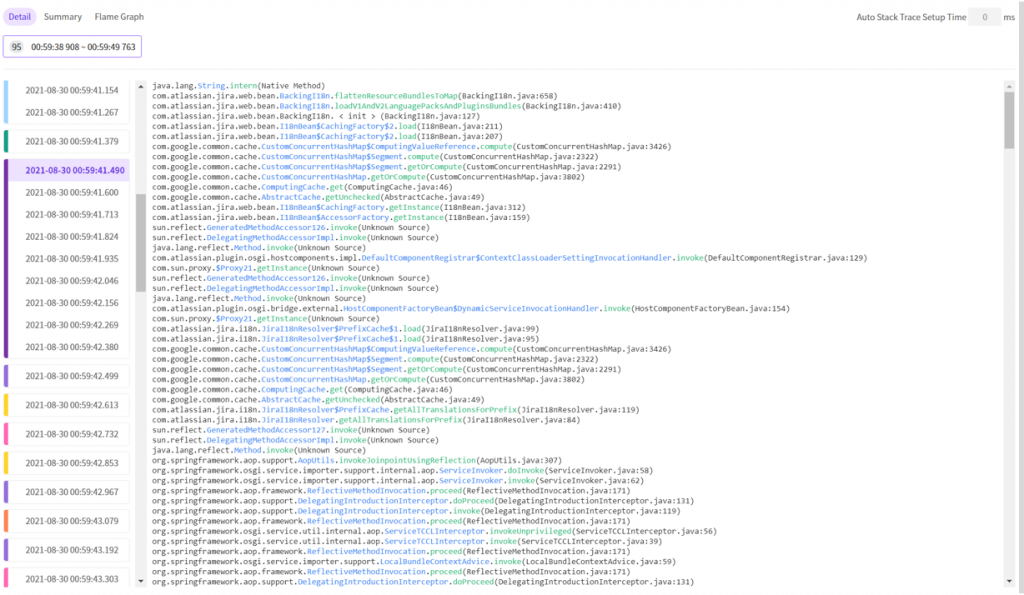
이전 타임 라인의 탭에서처럼 해당 시간 구간에 95개의 스택트레이스가 존재하는 것을 확인할 수 있습니다. (각 시간 앞에 표시된 색상은 스택트레이스의 종류를 뜻합니다.)
같은 색으로 이어진 구간이 있는 경우 연속으로 여러번 수집된 것이며 이 경우 오랫동안 실행 되었음을 유추할 수 있습니다. 즉 느린 메소드인 것이죠.
이 트랜잭션의 경우 유독 String.intern() 메소드가 여러번 호출 되고 있습니다.
스크롤을 하면서 동일한 색으로 이어진 부분을 찾을 수도 있지만 요약, Flame 그래프를 이용하면 더욱 쉽게 오랫동안 실행된 메소드를 찾을 수 있습니다.
1. 요약보기
요약 보기를 클릭하면 다음과 같은 내용을 확인할 수 있습니다.
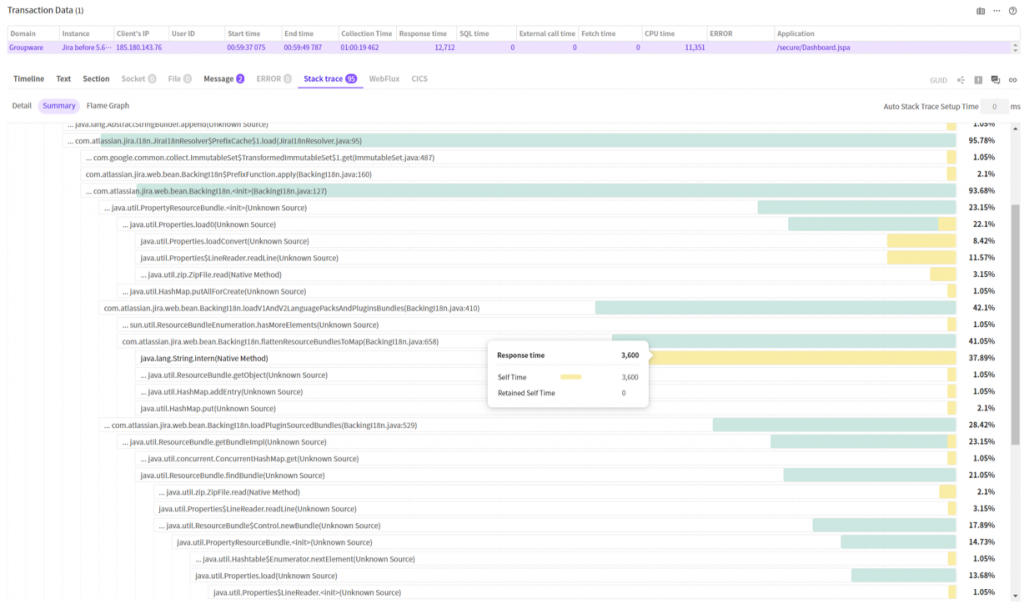
수집된 95개의 스택트레이스에 나타난 각 메소드의 호출관계를 통합하여 하나의 트리로 표현하고 있습니다.
여기서 노란색 막대가 가장 넓은 영역을 차지하는 노드를 찾으면 그것이 가장 많이 실행중이었던, 즉 가장 느린 메소드가 됩니다. String.intern() 메소드가 37.89% 를 차지하는 것을 알 수 있습니다. (시간으로는 3.6초 정도 걸렸군요.)
파란색으로 표시된 메소드들은 이러한 느린 메소드들을 포함한 메소드들입니다. 분석 관점에 따라 실행중이었던 메소드가 아닌 가장 많이 호출된 메소드부터 찾고자 하는 경우 이 노드들을 중점적으로 찾아나가면 됩니다.
2. Flame 그래프
이번에는 Flame 그래프로 확인해볼까요?
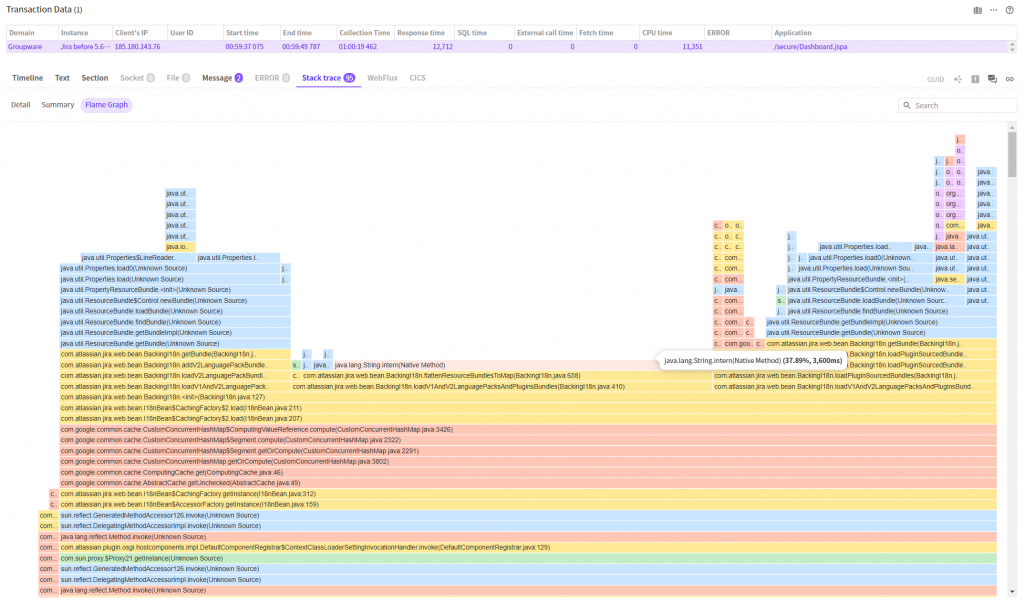
여기서는 흡사 불꽃 너울과 같은 모습의 차트를 확인할 수 있습니다.
각 네모 영역의 줄기의 최상단에 위치하면서 가장 넓은 부분을 차지하는 것이 가장 느린 메소드 입니다. 한눈에 봐도 java.lang.String.intern() 메소드가 가장 많이 실행중이었던 것을 알 수 있습니다.
한칸 아래의 메소드는 java.lang.String.intern() 메소드를 호출한 메소드인 com.atlassian.jira.web.bean.BackingI18n.flattenResourceBundlesToMap(BackingI18n.java:658) 메소드 입니다.
이렇게 3가지 방법을 통해 가장 오랫동안 실행중이었던 메소드는 String.intern, 이것을 호출한 메소드는 BackingI18n.flattenResourceBundlesToMap 이라는 결론에 도달했습니다.
이제 이 메소드들이 느린 이유가 궁금해지네요.
우선 BackingI18n 클래스를 확인하고 싶은데 패키지 이름을 잘 보니 atlassian, Jira 제품의 코드입니다. 우리가 소스 코드를 열어보거나 수정할 수 없다는 것이죠.
그럼 String.intern 메소드를 중점적으로 분석해 봅시다.
아주 기본적인 JDK 가 제공하는 네이티브 메소드로 JVM 이 관리하는 문자열 풀에 파라미터로 전달된 문자열이 문자열 풀에 없으면 넣은 뒤 반환 있으면 조회하여 반환합니다.
간단히 말해서 동일한 문자열을 중복으로 생성하지 않게하여 메모리 사용률을 줄일 수 있게 됩니다. 그런데 이것이 3초도 넘게 걸렸다니 뭔가 수상한 느낌이 들지 않나요? 🤨
다음과 같이 해당 메소드를 키워드로 검색을 해봅시다.
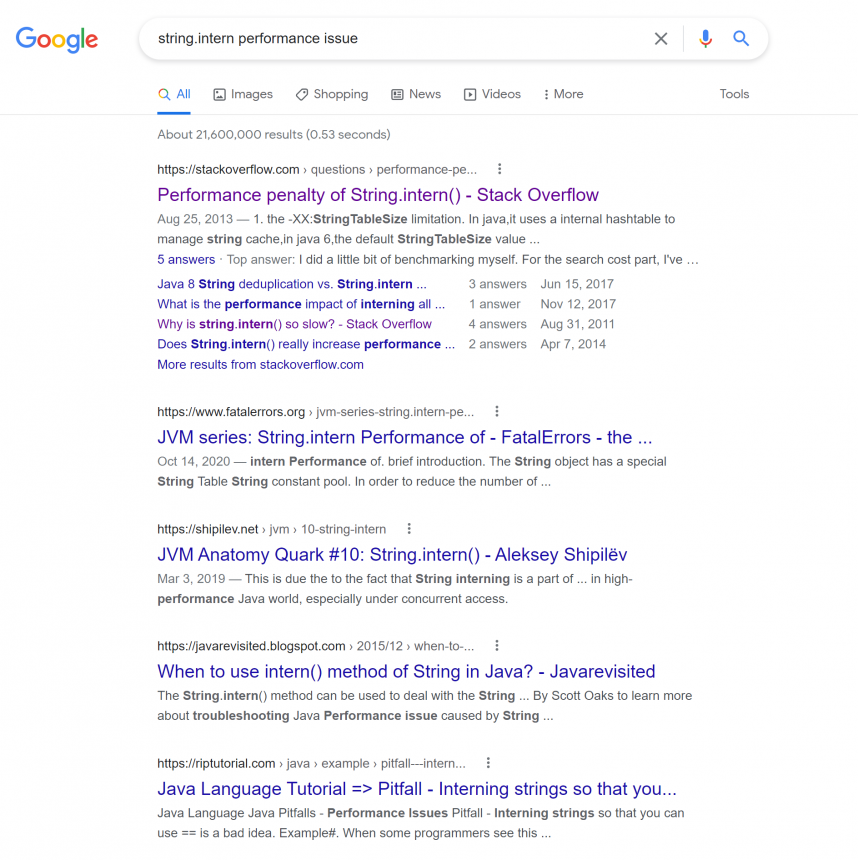
검색된 첫번째 결과를 들어가보니 JDK 버전별로 다르게 구현되어 동작하는 String.intern 메소드에 대한 정보를 확인할 수 있었습니다.
http://java-performance.info/string-intern-in-java-6-7-8/
위 링크의 내용을 간단하게 적어보면 다음과 같습니다.
- JDK6 – 문자열 풀이 PermGen 영역에서 관리되며 고정 크기이기 때문에 사용을 권장하지 않음. 직접 문자열 풀을 Map 계열로 구현하여 사용하는 것을 권장함
- JDK7 – 문자열 풀이 힙 영역에서 관리됨. jdku40 이전까지 풀의 기본크기 1009 임. jdku40 부터 60013 증가됨
- JDK8 – 문자열 풀이 힙 영역에서 관리됨. 기본 크기 60013
음? 생각해 보니 Y씨의 회사가 사용중인 Jira 는 상당한 구 버전이라고 했습니다.
혹시나 하여 사용중인 JDK 버전을 확인해봅니다. 🧐

아.. JDK 버전이 1.7.0_25 입니다. ☝️
그렇다면 문자열 풀의 기본 크기가 1009 이고 이것보다 많은 문자열들이 지속적으로 누적되면서 적절한 해시 분산이 이루어지지 못하고 있는 상황이라는 가정을 해봅시다. (맵 내의 데이터가 적절한 해시 알고리즘으로 분산되지 않으면 데이터의 건수가 많아질수록 조회 속도가 느려집니다.)
이것이 성능 저하의 실제 원인이라면 문자열 풀의 크기를 늘려서 어느 정도의 성능 개선의 효과를 기대할 수 있을 것입니다.
다음과 같이 Jira 실행 스크립에 문자열 풀 크기를 설정해주었습니다. 크기는 JDK8 의 기본 크기와 동일한 수치를 이용했습니다.

이제 Jira 를 재시작 후 상태를 지켜보기로 합니다.
그로부터 약 한달 후
옵션 적용 후 Jira 의 응답속도는 크게 개선 되었습니다. 이 글의 마무리를 짓고 있는 이 시점에도 전과는 비교할 수 없을만큼 쾌적 하다고 느끼고 있습니다. (개인의 성향에 따라 성능 개선 정도는 차이가 있을 수 있겠지만요. 🙂)
혹시나 하여 설정 변경전의 성능 정보를 제니퍼로 수집하여 남겨놓았습니다. 어느 정도의 개선이 있는지 개인적으로 궁금했기 때문입니다.
체감상 빨라진 부분을 좀 더 수치로 확인하고 싶어 애플리케이션 현황, 성능브라우저와 같은 기능을 이용해 이전과 현재의 상태를 비교해봤습니다.😙
1. 애플리케이션 현황
아래 내용은 호출건수로 내림차순 정렬하여 조회했습니다.
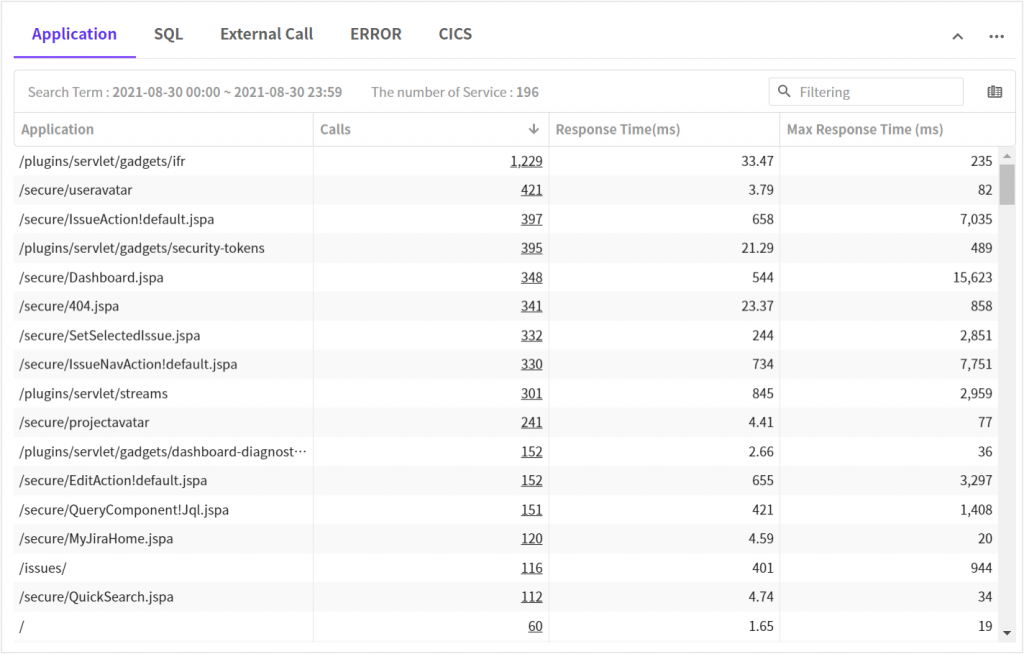
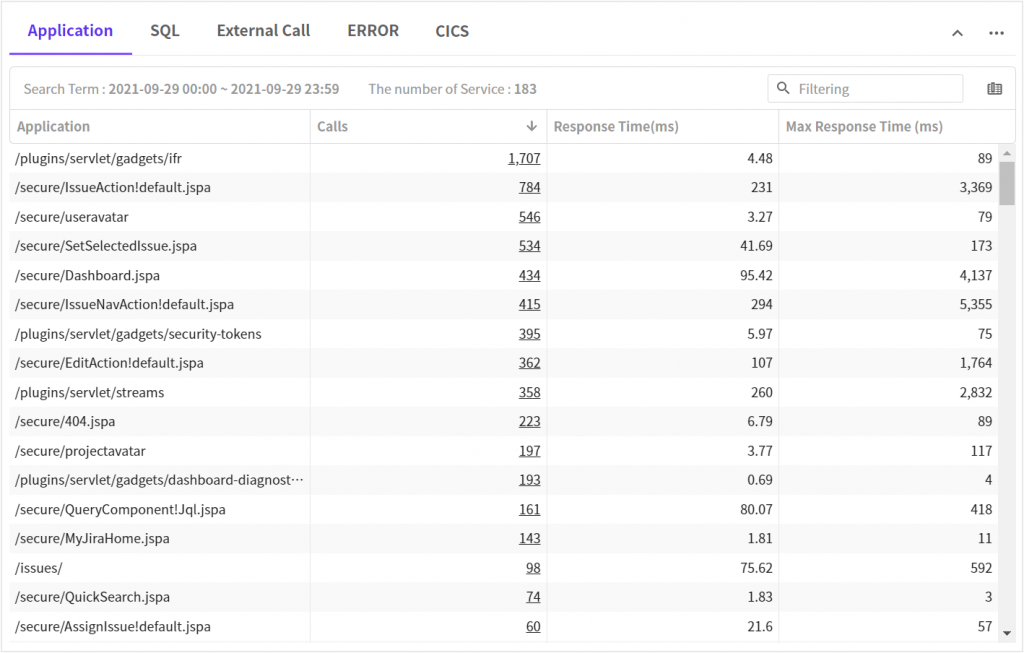
간단히 비교해봐도 평균, 최대 응답시간이 개선된 것을 확인할 수 있습니다.
2. 성능 브라우저
응답시간
이번에는 성능에 영향을 미치는 몇가지 요소들을 성능 브라우저 기능을 이용해 비교해봤습니다.
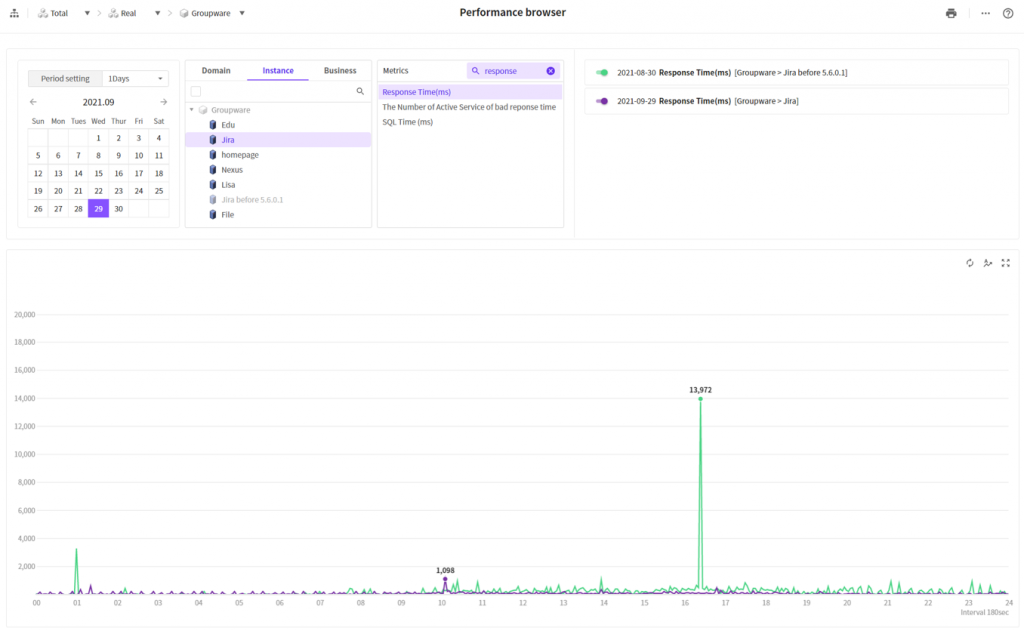
녹색이 기존, 보라색 라인이 적용 후 한달이 지난 시점의 상태입니다. 일반적인때나 피크시점의 시간이 전반적으로 개선된 것을 알 수 있습니다.
트랜잭션 당 CPU 시간
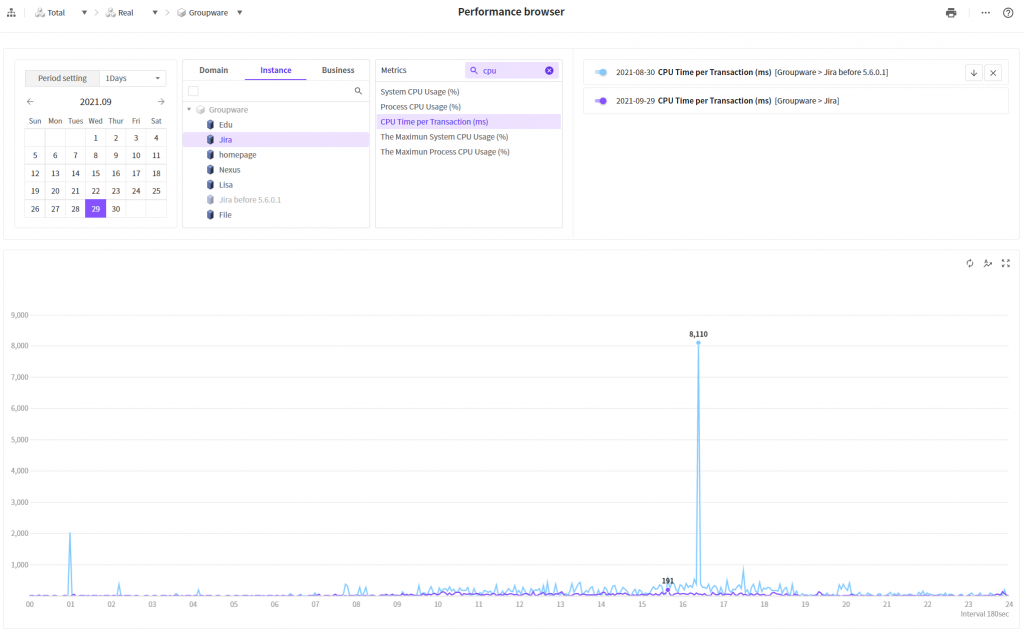
하늘색 라인이 개선전, 보라색 라인이 개선 후 입니다.
여기서도 개선 후 트랜잭션당 CPU 시간이 크게 감소한 것을 확인할 수 있습니다.
체감상 개선된 부분이 실제로 수치로 증명된 것이죠! 😚
3. X-View
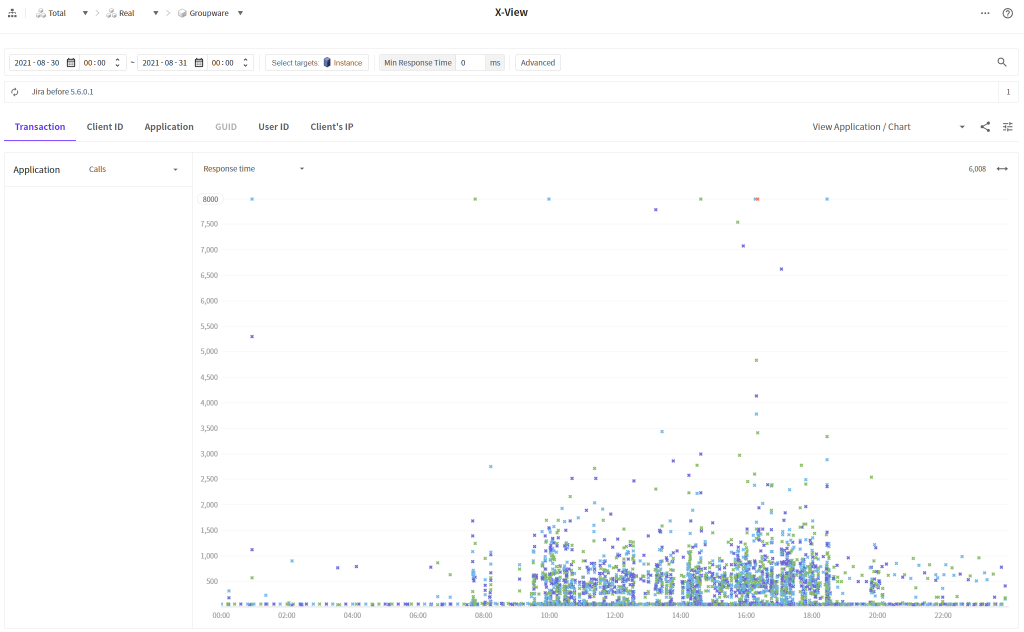
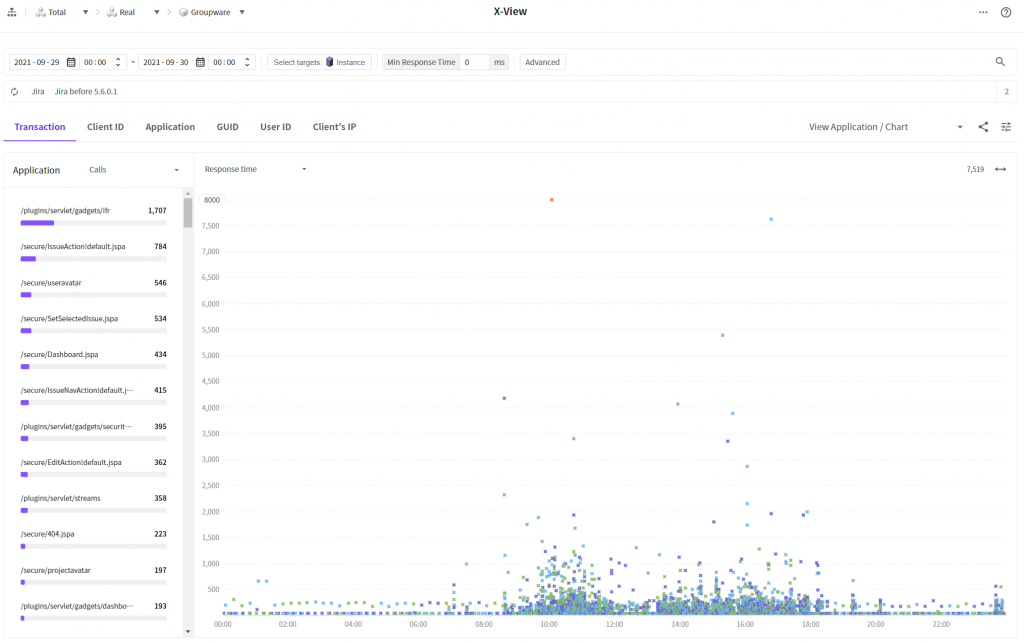
마지막으로 X-View 차트로 개선 전 후의 데이터를 비교해봤습니다.
전반적으로 트랜잭션들이 좀 더 아래로 오밀조밀 모였있는 것을 확인할 수 있습니다. 전반적인 응답시간이 개선 되었음을 의미합니다. 😊
결론
개선된 스택트레이스 기능을 소개하기에 앞서 사실 조금은 걱정이 되었습니다.
제가 경험한 샘플링 기반 분석 기능의 효과를 사용자에게 전달하기 위한 적절한 예를 찾기 어려웠기 때문입니다.
마침 운좋게도 주기적으로 성능이 나빠지는 현상을 보이는 설치형 Jira(이슈관리 시스템) 덕분에 실제로 사용하는 시스템의 성능 개선과 사용자에게 적절한 예로 소개할 수 있는 기회를 얻게 되었습니다.
소개한 사례와 같은 경우 일반적인 메소드 프로파일링 기법으로는 이러한 결과 도출이 매우 어려웠을 것입니다.
java.lang 패키지를 프로파일링 한다는 것은 올바른 접근 방법이 아니며 문제로 밝혀진 String.intern 메소드는 네이티브 메소드이기 때문이죠.
이번 소개한 제니퍼의 기능이 그냥 지나쳐버릴 수 있는, 혹은 포기해버린 개선 지점을 찾아 해결하는데 도움이 되길 바라며 본 글을 마칩니다.
제니퍼는 개별 트랜잭션의 스택트레이스 뿐 아니라 시스템 전체의 스택트레이스를 기반으로 한 분석 기능을 준비하고 있습니다. 트랜잭션 관점에서 분석할 수 없는 성능 이슈를 해결하는데 도움이 될 기능이니 기대해주세요. 😍
