16. 알람 시스템 구축 – Robusta & 그라파나

1. 모니터링과 알람 : 시스템 운영의 핵심 요소
필자는 시스템 운영에서 가장 중요한 요소는 모니터링과 알람이라 생각합니다.
시스템의 현재 상태를 알람을 통해 신속하고 자동으로 파악하는 것은 운영의 효율성을 크게 높여줍니다. 복잡한 절차 없이도 중요한 정보를 놓치지 않고 바로 알 수 있는 것이 알람 시스템의 핵심 가치입니다. 운영자가 일일이 수많은 시스템의 상태를 확인하는 것은 불가능합니다.
물론 얼핏 간단해 보이지만, 실제로 효과적인 알람 시스템을 구현하는 것은 상당한 도전과제입니다. 장애가 발생한 후에야 알람 설정의 미흡함을 깨닫는 것은 너무나 흔한 일입니다. 이러한 상황을 미연에 방지하고, 신속하게 대응할 수 있는 능력이 바로 뛰어난 시스템 관리자나 DevOps 전문가를 구별하는 기준이라 할 수 있습니다. 그리고 한번에 구현할 수 없어 끊임없이 최적화가 필요한 작업입니다.
쿠버네티스도 기존의 모든 IT 서비스와 동일하게 제대로 동작하는 알람 시스템을 구성하는 것은 매우 중요한 일입니다.
2. 알람 시스템의 전제 조건
그럼 쿠버네티스 환경의 알람 시스템은 어떠한 요소를 만족해야 할까요? 기존 시스템과 동일하게 쿠버네티스도 아래의 조건들을 만족하는 것이 중요합니다.
- 미흡한 부문이 없는 다양한 알람 – 복잡한 쿠버네티스의 상태를 확인할 수 있는 전체 상태의 알람을 제공하는가?
알람 시스템은 다양한 운영 상황과 장애 조건을 포괄할 수 있어야 합니다. 시스템의 모든 중요한 측면을 모니터링 할 수 있는 완전한 알람 유형이 사전에 설정되어 있어야 합니다. 컨설팅 업계에서 많이 사용하는 MECE(Mutually Exclusive, Collectively Exhaustive) 중복되지 않고 전체를 포함하는 알람이 필요합니다. - 메시지의 가독성과 명확성 – 메시지만 보고 시스템 관리자 혹은 서비스 담당자는 어떠한 문제인지 빠르게 파악할 수 있는가?
알람 메시지는 분명하고 단순하고 이해하기 쉬워야 합니다. 관리자가 메시지를 빠르게 읽고 문제의 본질을 즉시 파악할 수 있어야 합니다.
- 중복 메시지와 경보 빈도 – 유사한 메시지가 너무 자주 발생하여 알람 피로도가 발생하지 않는지? 중요하지 않은 메시지로 인하여 정작 중요한 메시지는 놓치는 경우가 발생하지 않는지?
너무도 흔한 문제입니다. 알람 피로도 역시 중요한 요소입니다. 경험을 통한 적절한 빈도 설정이 필요합니다. 알람 설정만큼이나 불필요한 알람을 제거하는 작업 역시 중요합니다. 물론 상대적으로 덜 중요하다는 이유로 간과되는 경과가 많습니다.
- 적시성 – 문제가 발생하면 빠르게 알람이 발생하는가?
알람은 문제가 발생하는 즉시, 혹은 가능한 한 빨리 발송되어야 합니다. 이를 통해 관리자가 신속하게 대응할 수 있도록 해야 합니다. 더 큰 문제가 발생하기 전에 최대한 빠른 처리가 필요합니다. - 예방적 알람 – 가능하다면 문제가 발생하기 전에 징후를 포착하여 미리 알람을 알려주는가? 혹은 서비스에 영향이 큰 문제가 발생하기 전에 미리 작은 문제를 알려줄 수 있는가?
알람 시스템은 잠재적 문제나 장애를 미리 감지하고 경고하여, 문제가 발생하기 전에 예방 조치를 취할 수 있도록 해야 합니다. - 기본 운영 기능 제공
알람 시스템은 ‘Sleep(일시 중지)’ 모드와 같은 기본적인 운영 기능을 제공해야 하며, 이를 통해 필요에 따라 알람을 조절하거나 일시적으로 중단할 수 있어야 합니다. 시스템 정기 작업 시 알람을 일시 중지하는 경우가 대표적입니다. - 알림 설정의 용이성
사용자가 손쉽게 추가 알람을 설정하고 조정할 수 있어야 합니다. 시스템 변화나 새로운 요구 사항에 빠르게 대응하는 데 필수입니다. - 통합 및 확장성
알람 시스템은 기존 모니터링 시스템과 원활하게 통합되고, 필요에 따라 쉽게 확장할 수 있어야 합니다. 다양한 환경과 도구와의 호환성도 중요합니다.
그럼 이러한 조건들을 어떻게 만족해야 하는지 실습과 함께 알아보겠습니다.
3. 프로메테우스 Alert Rules
프로메테우스 커뮤니티 헬름 차트로 설치하면 기본으로 쿠버네티스 운영에 필수적인 다양한 Alert Rules가 포함되어 있습니다. 해당 Rule은 아래와 같이 prometheusRules 커스텀 리소스로 확인할 수 있습니다. ‘promehteusrules’도 별도의 쿠버네티스 리소스로 ‘k get’ 명령어로 확인할 수 있습니다.
(jerry-test:monitoring)~$ k get prometheusrules.monitoring.coreos.com -A NAMESPACE NAME AGE monitoring prometheus-kube-prometheus-alertmanager.rules 13h monitoring prometheus-kube-prometheus-config-reloaders 13h monitoring prometheus-kube-prometheus-general.rules 13h monitoring prometheus-kube-prometheus-k8s.rules 13h monitoring prometheus-kube-prometheus-kube-prometheus-general.rules 13h monitoring prometheus-kube-prometheus-kube-prometheus-node-recording.rules 13h monitoring prometheus-kube-prometheus-kube-state-metrics 13h monitoring prometheus-kube-prometheus-kubelet.rules 13h monitoring prometheus-kube-prometheus-kubernetes-apps 13h monitoring prometheus-kube-prometheus-kubernetes-resources 13h monitoring prometheus-kube-prometheus-kubernetes-storage 13h monitoring prometheus-kube-prometheus-kubernetes-system 13h monitoring prometheus-kube-prometheus-kubernetes-system-apiserver 13h monitoring prometheus-kube-prometheus-kubernetes-system-kube-proxy 13h monitoring prometheus-kube-prometheus-kubernetes-system-kubelet 13h monitoring prometheus-kube-prometheus-node-exporter 13h monitoring prometheus-kube-prometheus-node-exporter.rules 13h monitoring prometheus-kube-prometheus-node-network 13h monitoring prometheus-kube-prometheus-node.rules 13h monitoring prometheus-kube-prometheus-prometheus 13h monitoring prometheus-kube-prometheus-prometheus-operator 13h redis redis 10d
다양한 Rule을 확인할 수 있습니다. 따로 설정하지 않았는데 이미 다양한 Ruel이 포함되어 있습니다. 뿐만 아니라 각각의 상세한 Rule을 describe 명령어로 확인하면 단일 알람이 아닌 여러 개의 알람 Rule로 되어 있는 것을 알 수 있습니다.
(jerry-test:monitoring)~$ k describe prometheusrules.monitoring.coreos.com prometheus-kube-prometheus-kubernetes-apps
Name: prometheus-kube-prometheus-kubernetes-apps
(중략)
Rules:
Alert: KubePodCrashLooping
Annotations:
Description: Pod {{ $labels.namespace }}/{{ $labels.pod }} ({{ $labels.container }}) is in waiting state (reason: "CrashLoopBackOff").
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/kubernetes/kubepodcrashlooping
Summary: Pod is crash looping.
Expr: max_over_time(kube_pod_container_status_waiting_reason{reason="CrashLoopBackOff", job="kube-state-metrics", namespace=~".*"}[5m]) >= 1
For: 15m
Labels:
Severity: warning
상세 설정을 확인하면 위 Rule은 파드의 상태가 ‘CrashLoopBackOff(reason)’로 15m(For) 지속되면 ‘warning’ 심각도(Severity) 경보를 발생하는 설정입니다. 이처럼 비슷한 설정이 다른 Rule 에서도 포함되어 있습니다. 각 Rule마다 상세 내용을 확인할 수 있습니다.
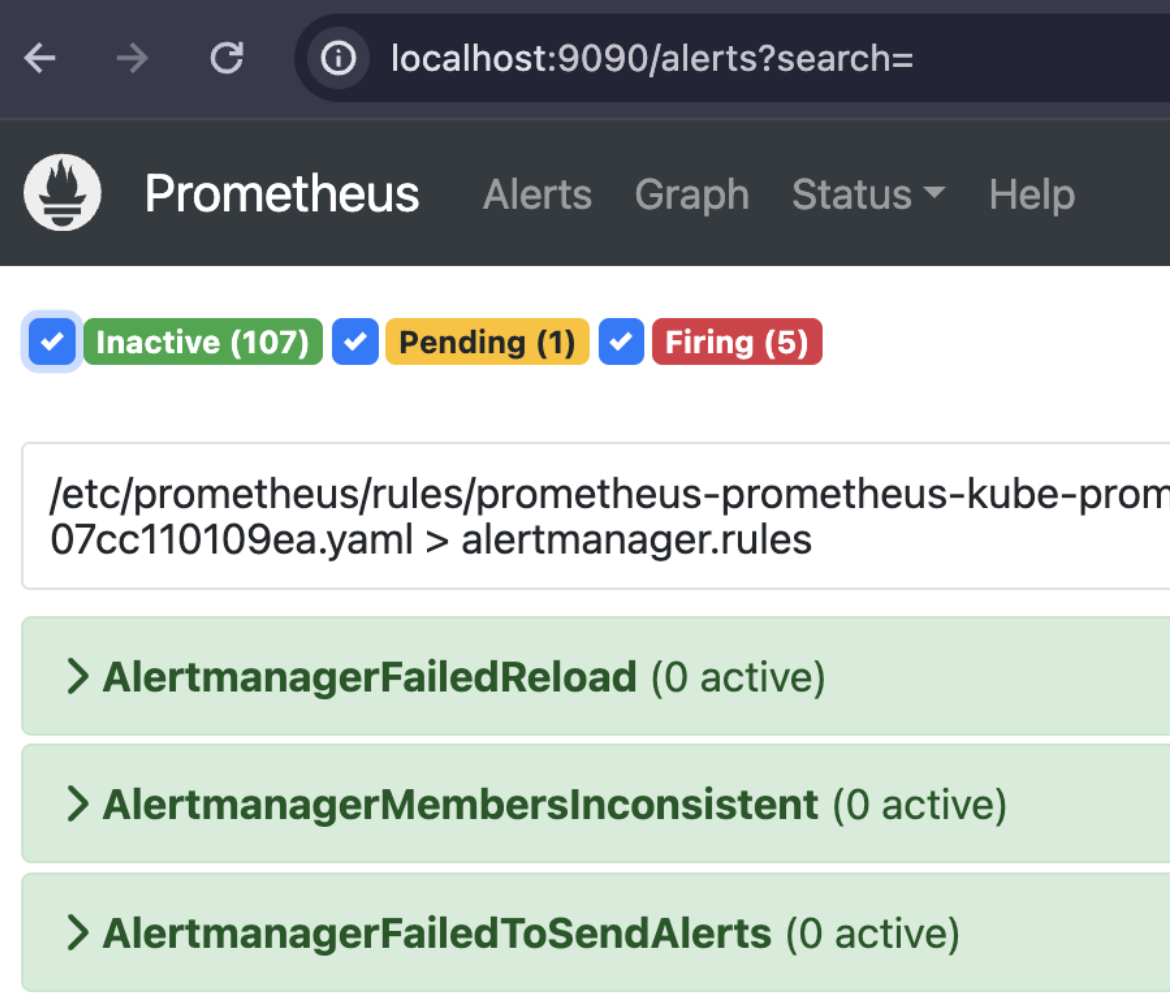
명령어 뿐만 아니라 전체 Alert Rule 리스트는 Prometheus GUI에서도 확인할 수 있습니다.
(jerry-test:monitoring)~$ k port-forward svc/prometheus-kube-prometheus-prometheus 9090:9090 Forwarding from 127.0.0.1:9090 -> 9090 Forwarding from [::1]:9090 -> 9090
화면 상단의 ‘Alerts’ 메뉴를 선택하면 아래와 같이 ‘113’개의 Rule을 확인할 수 있습니다. 필자의 운영 경험 상 사전에 제공하는 이 Alert Rule 만으로 애플리케이션 알람을 제외하고 기본 쿠버네티스 클러스터 운영에 필요한 거의 전부가 포함되어 있습니다. 그리고 In-House에서 만든 애플리케이션과 Kafka, MySQL 등의 Public 애플리케이션에 대한 알림 설정은 그라파나 대시보드에서 별도로 Alert Rule을 만들 수 있습니다.
4. 슬랙 알람 채널 준비
그럼, 알람을 받을 채널을 설정하겠습니다. 알람을 받을 채널은 슬랙을 이용합니다. 이메일도 가능하나 히스토리 조회, 상세 채널 분리 및 여러 사람들이 함께 볼 수 있는 개방성 측면에서 슬랙이 유리하다 생각합니다.
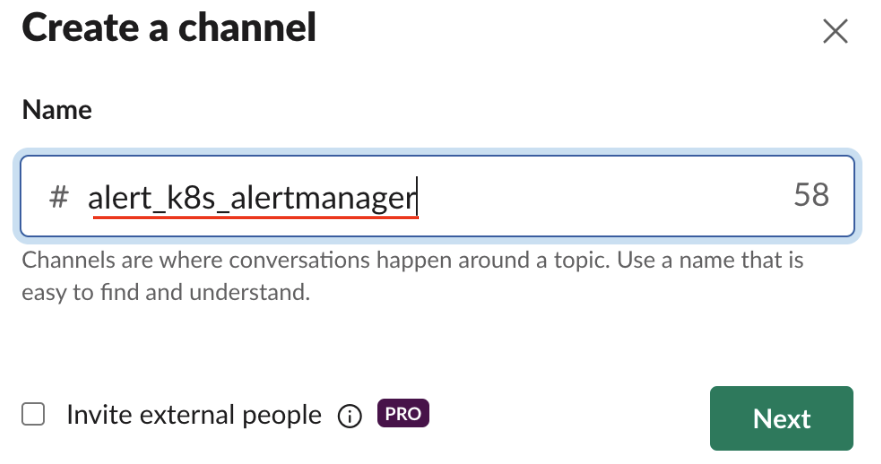
슬랙에서 쿠버네티스 알람을 받을 새로운 채널을 생성합니다. 이름은 임의로 아래와 같이 정할 수 있습니다. 하지만 앞으로 유사한 Alert 채널을 만들 예정이므로 미리 ‘이름 규칙(Naming Convention)’을 지정하는 것을 권고합니다. 필자는 ‘alert_k8s_alertmanager’로 지정하였습니다. ‘alertmanager’는 프로메테우스 제공하는 알람 관련 리소스 이름입니다.
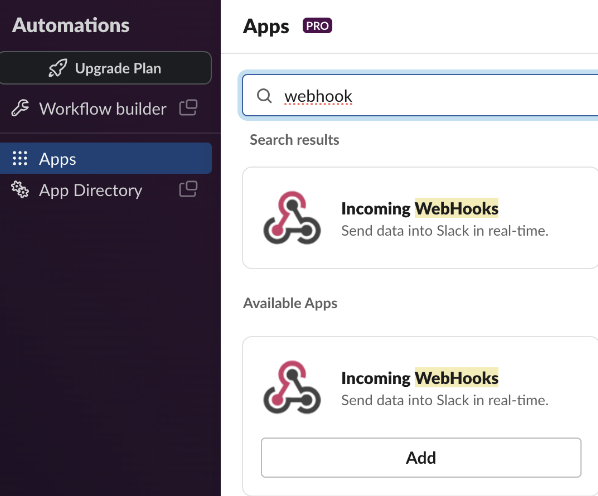
‘WebHooks’를 이용하여 쿠버네티스 알람을 전송할 예정이므로 슬랙의 ‘Apps’ 메뉴를 선택하고 ‘webhook’을 입력합니다.
웹훅은 웹 애플리케이션 간에 데이터를 전송하기 위한 방법 중 하나입니다. 이는 일종의 HTTP 콜백(callback)으로서, 두 개 이상의 웹 애플리케이션 간에 특정 이벤트가 발생할 때 다른 애플리케이션에 알림을 보내고자 할 때 많이 사용됩니다.
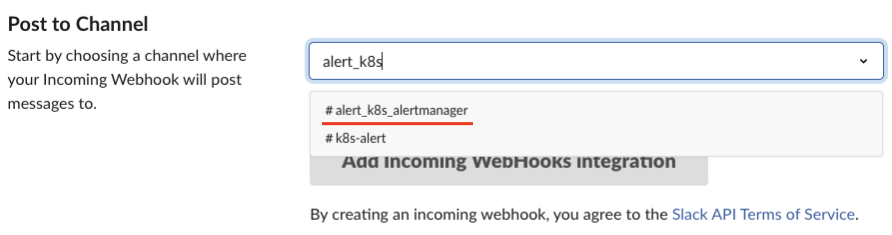
‘WebHooks’를 선택하고 이어지는 화면에서 방금 생성한 채널을 선택합니다.
채널 이름을 입력하면 아래와 같은 ‘Webhook URL’ 확인할 수 있습니다. 외부 서비스에서 해당 URL을 이용하여 슬랙에 메시지를 전달합니다. 해당 URL이 노출되면 다른 사용자가 임의로 해당 리소스를 사용할 수 있으니 깃헙 등에 공개하지 않도록 유의합니다.
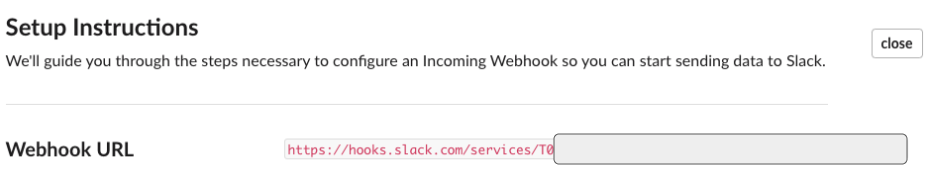
이어지는 설정에서 해당 URL을 사용할 예정이므로 잘 보관합니다.
5. 프로메테우스-커뮤니티 헬름 차트를 이용한 AlertManager 설치
Alertmanager는 프로메테우스에서 제공하는 애플리케이션에서 보낸 알람을 처리하는 도구입니다. 이는 중복 제거, 그룹화, 올바른 수신자 통합(예: 이메일, PagerDuty, OpsGenie)으로 알람을 라우팅하는 역할을 하며, 알람의 침묵(silencing) 및 억제(inhibition) 기능도 제공합니다. 알람 설정에서 억제란 유사한 알람이 중복해서 발생하지 않는 기능을 의미합니다.
앞에서 살펴본 프로메테우스 아키텍처 그림에서 ‘AlertManager’는 오른쪽 상단에 위치한 알람 기능을 담당하고 있습니다.
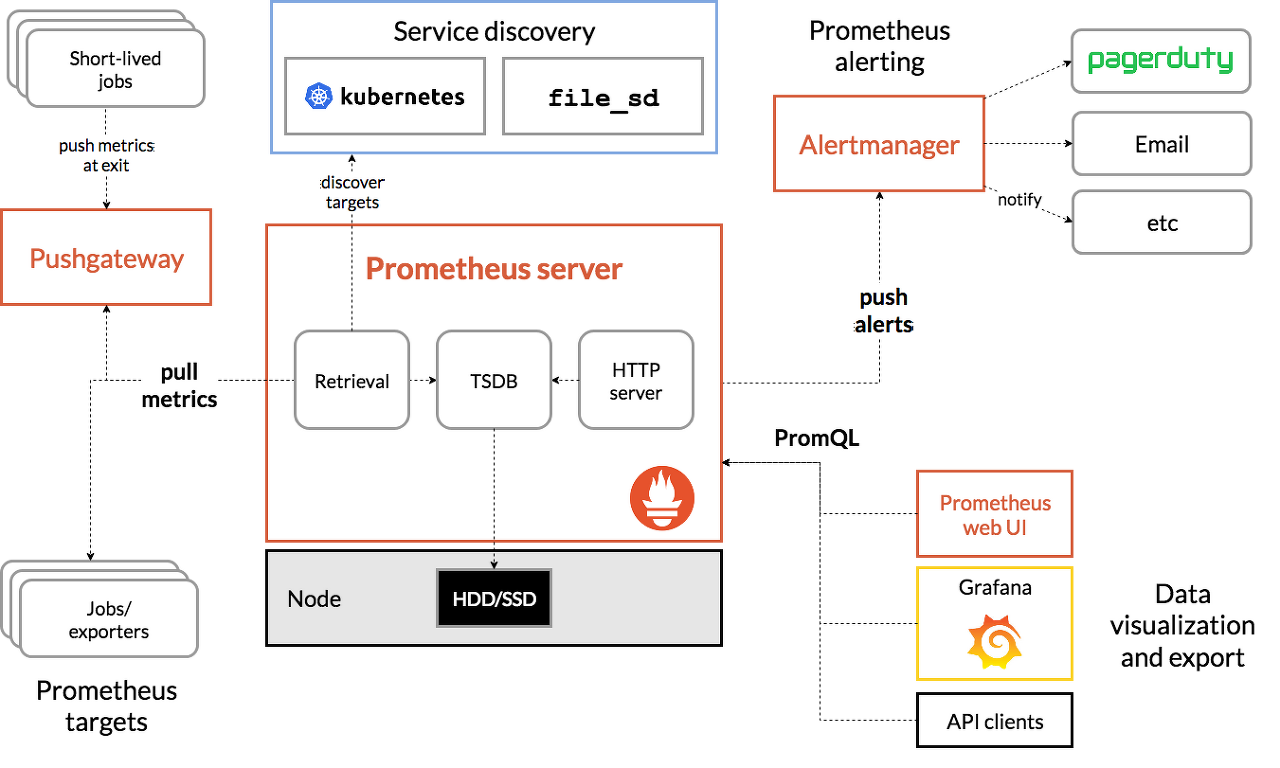
그라파나와 동일하게 편리하게 프로메테우스-커뮤니티 헬름 차트에 관련 설정을 통합해서 제공합니다.
## Configuration for alertmanager
alertmanager:
enabled: true
config:
route:
group_by: ['namespace']
group_wait: 30s
group_interval: 2m
repeat_interval: 6h
receiver: 'slack-notifications'
routes:
- receiver: 'slack-notifications'
matchers:
- alertname =~ "InfoInhibitor|Watchdog"
receivers:
- name: 'slack-notifications'
slack_configs:
- api_url: "{{ SLACK_API }}" # 여기에 Slack Webhook URL을 넣습니다.
channel: '#alert_k8s_alertmanager' # 메시지를 보낼 Slack 채널
send_resolved: true
title: '{{ template "slack.default.title" . }}'
text: "summary: {{ .CommonAnnotations.summary }}\ndescription: {{ .CommonAnnotations.description }}"
. alertmanager.config.route.receiver: slack-notifications
알람 전송 채널로 slack을 이용합니다. 만약 email을 사용하면 ‘email-config’ 설정을 사용합니다. 슬랙은 자주 사용하는 설정으로 Values 파일에서 표준 설정을 제공합니다.
. receivers: slack_config.api_url
앞에서 생성한 WebHook URL 정보를 입력합니다. 깃헙 등에서 외부에 노출되지 않도록 주의합니다.
. receivers: slack_config.channel
채널 이름을 지정합니다. 필자는 ‘alert_k8s_alertmanager’로 지정하였고 각자 이름을 입력합니다.
추가로 ‘send_resolved’ 는 알람이 해결된 메시지를 보내는 설정이며, title과 text 설정은 이름 그대로 알람 메시지의 제목과 내용을 지정하는 내용입니다.
해당 설정을 추가하고 프로메테우스 헬름을 업그레이드(helm upgrade) 합니다. ‘diff’ 명령어로 먼저 확인하고 업그레이드 작업을 진행합니다.
(jerry-test:monitoring)kube-prometheus-stack-48.3.1$ helm diff upgrade prometheus -f ci/my-values.yaml . (jerry-test:monitoring)kube-prometheus-stack-48.3.1$ helm upgrade prometheus -f ci/my-values.yaml .
AlertManager는 별도의 UI를 제공합니다. UI를 통해서 설정 내역을 확인해 보겠습니다. port-forward를 이용하여 접속합니다.
(jerry-test:monitoring)~$ k port-forward svc/prometheus-kube-prometheus-alertmanager 9093:9093 Forwarding from 127.0.0.1:9093 -> 9093 Forwarding from [::1]:9093 -> 9093
화면 상단의 메뉴 ‘Status’를 선택합니다.
Alertmanager 관련 설정과 상태(‘Status’) 정보를 확인할 수 있습니다. 아래를 확인하면 헬름 차트에 수정한 ‘slack_configs’ 관련 설정이 정상으로 추가된 것을 확인할 수 있습니다.

정상 설정이 되면 슬랙에서 알람을 확인할 수 있습니다. 아래 ‘Watchdog’ 메시지는 AlertManager에 슬랙이 정상으로 연동되면 발송되는 메세지입니다. AlertManager 자체가 문제가 발생하여 알림을 받지 못하는 경우가 발생할 수 있는데 ‘Watchdog’ 메시지로 정상 여부를 판단할 수 있습니다.

하지만 필자가 생각하기에 ‘AlertManager’는 부족합니다. 실제 모의로 장애를 발생한 경우 AlertManager에서 발송하는 메시지가 불명확하여 한번에 장애 원인을 찾기 어렵습니다. UI도 그리 직관적이지 않습니다.
실습으로 임의로 ‘CrashLoopBackOff’ 파드를 실행합니다.
(jerry-test:default)~$ kubectl apply -f https://raw.githubusercontent.com/robusta-dev/kubernetes-demos/main/crashpod/broken.yaml
5분의 상태 확인 시간과 15분의 장애 지속 시간이 지나고 20분이 경과하면 아래의 메시지를 경고 메시지를 확인할 수 있습니다.
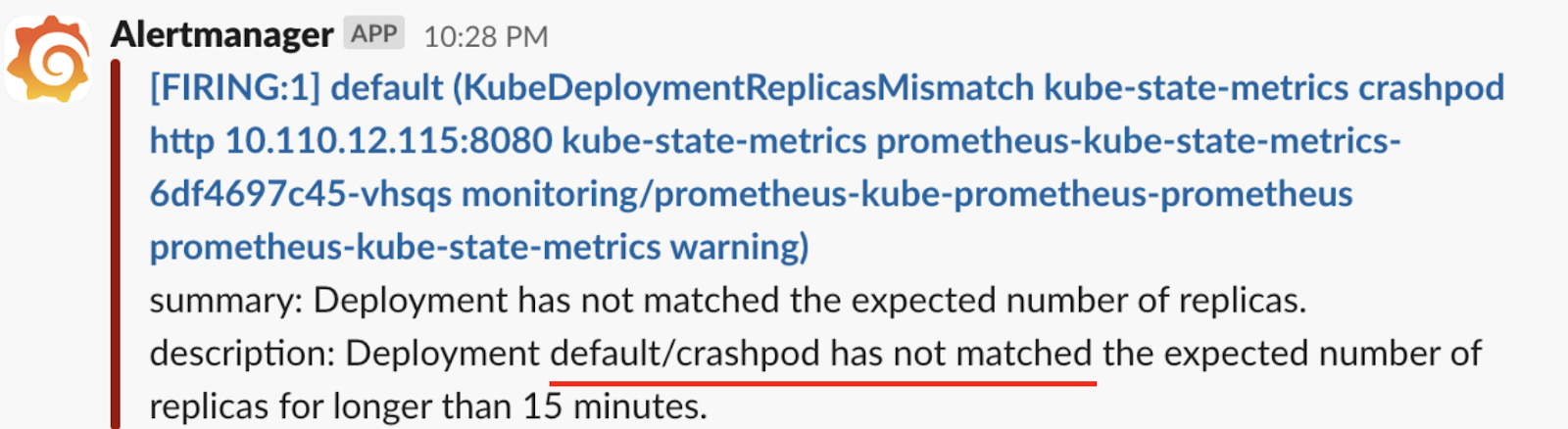
경고 시간 간격 설정은 수정이 가능합니다. 하지만 각각의 설정을 일일이 수정하는 것은 번거로워 간과하기 쉬운 작업입니다. 그리고 경고 메시지가 직관적이지 않아 한번에 파악이 쉽지 않습니다.
필자는 추가 알람 시스템으로 Robusta을 사용합니다. 이어지는 파트에서 확인하겠습니다.
참고로 ‘CrashLoopBackOff’ 문제를 해결하면 아래의 해결 완료(‘RESOLVED’) 메시지가 전송됩니다.

6. Robusta – 직관적인 알림 시스템
Robusta는 쿠버네티스(Kubernetes) 클러스터를 위한 자동화된 알람 및 문제 해결 플랫폼입니다. 앞에서 살펴본 알럿매니저 보다 보다 직관적인 알람 메시지를 전송하는 것이 장점입니다. 위 ‘CrashLoopBackOff’ 알람 사례인데 보다 직관적입니다.
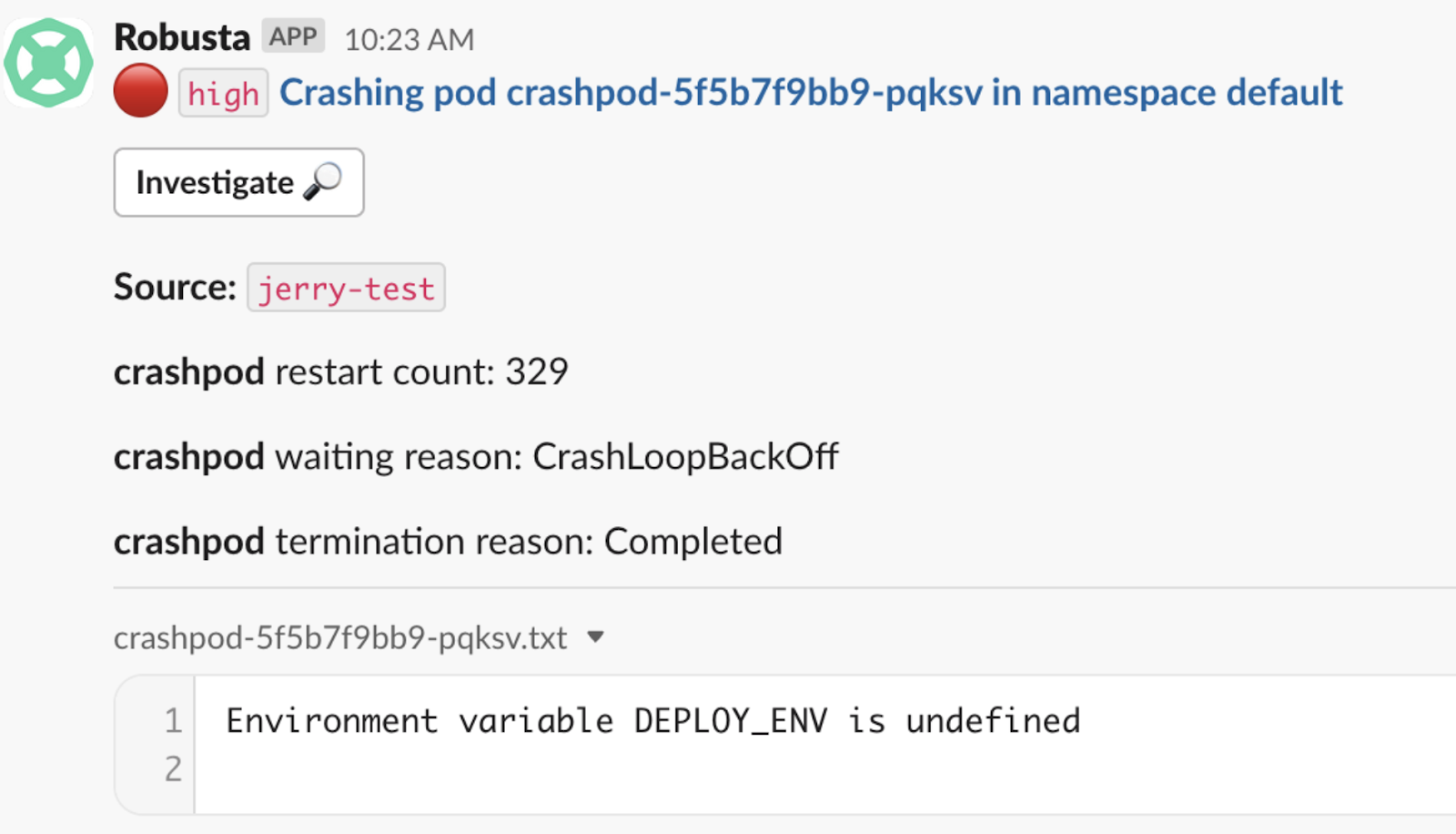
플랫폼은 쿠버네티스 시스템의 이벤트와 메트릭을 실시간으로 모니터링하고, 잠재적 문제가 발생했을 때 자동으로 알림을 발송합니다. 사용자는 Robusta를 통해 쿠버네티스 클러스터의 운영 효율성을 향상시킬 수 있으며, 알람 관리와 대응 과정을 간소화할 수 있습니다.
공식 홈페이지 가이드에 따라 Robusta를 설치합니다. 헬름으로 바로 설치하지는 못하고 설정 관련 보안 정보가 필요하여 robusta CLI를 이용하여 먼저 설정 파일을 생성합니다.
[(jerry-test:default) ~]$ pip3 install -U robusta-cli --no-cache
robusta 설치 시 프로메테우스를 같이 설치할수도 있으나 일반적으로 프로메테우스가 설치된 환경에서 추가로 설치하는 경우가 많으므로 프로메테우스를 설치하지 않는 옵션(–no-enable-prometheus-stack)을 선택합니다. 추가로 SSL 관련 에러가 에러가 발생하지 않도록 아래의 인증서 관련 명령어를 사전에 실행합니다.
(jerry-test:redis)robusta$ security find-certificate -a -p > ~/all_mac_certs.pem; (jerry-test:redis)robusta$ export SSL_CERT_FILE=~/all_mac_certs.pem; (jerry-test:redis)robusta$ export REQUESTS_CA_BUNDLE=~/all_mac_certs.pem (baas-dev-01:monitoring)~$ robusta gen-config --no-enable-prometheus-stack --debug Robusta reports its findings to external destinations (we call them "sinks"). We'll define some of them now. Configure Slack integration? This is HIGHLY recommended. [Y/n]: n Configure MsTeams integration? [y/N]: Configure Robusta UI sink? This is HIGHLY recommended. [Y/n]: Enter your Google/Gmail/Azure/Outlook address. This will be used to login: erdia22@gmail.com Choose your account name (e.g your organization name): My-Robusta Successfully registered. Please read and approve our End User License Agreement: https://api.robusta.dev/eula.html Do you accept our End User License Agreement? [y/N]: y Last question! Would you like to help us improve Robusta by sending exception reports? [y/N]: y Saved configuration to ./generated_values.yaml - save this file for future use! Finish installing with Helm (see the Robusta docs). Then login to Robusta UI at https://platform.robusta.dev
기본 설정에 따라 설치하였으며 Slack 관련 설정은 설치 후 추가할 수 있어 기본 설정 옵션을 변경하여 ‘n’으로 선택하였습니다. 추후 슬랙 관련 설정으로 설명하겠습니다.
명령어를 실행한 디렉토리를 확인하면 ‘./generated_values.yaml’ 파일을 확인할 수 있습니다. 해당 파일은 Robusta 설치에 필요한 계정 정보와 토큰 정보 등 보안에 민감한 정보가 포함되어 있습니다. 보안을 위하여 외부 깃허브 등에 공개하지 않습니다. 필요하다면 ‘SOPS’ 등 암호화 모듈을 사용해서 공유 합니다.
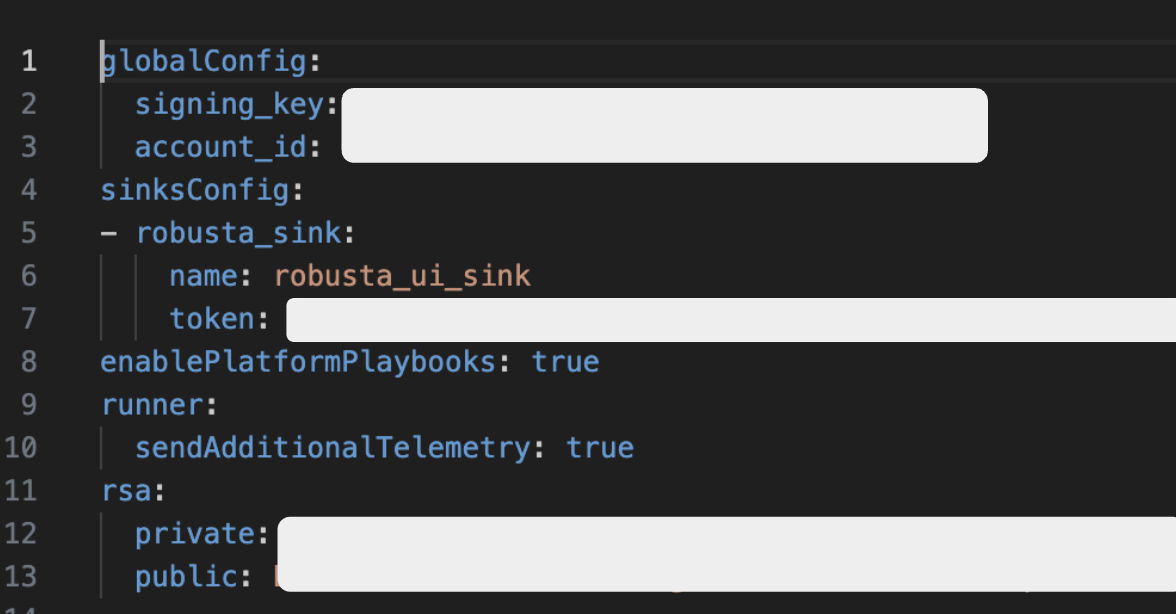
이제 설치를 위하여 Robusta 헬름 파일을 내려받습니다.
(jerry-test:redis)robusta$ helm repo add robusta https://robusta-charts.storage.googleapis.com && helm repo update "robusta" has been added to your repositories (baas-dev-01:monitoring)robusta$ helm pull robusta/robusta (baas-dev-01:monitoring)robusta$ tar xvfz robusta-0.10.25.tgz (baas-dev-01:monitoring)robusta$ rm -rf robusta-0.10.25.tgz (baas-dev-01:monitoring)robusta$ mv robusta/ robusta-0.10.25
이전에 저장한 설정 파일(~/generated_values.yaml)을 이용하여 설치합니다. clusterName은 각자 이름으로 변경합니다.
(baas-dev-01:monitoring)robusta-0.10.25$ helm install robusta -f ~/generated_values.yaml --set clusterName=baas-dev-01 . NAME: robusta LAST DEPLOYED: Sun Dec 10 14:09:41 2023 NAMESPACE: monitoring STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: Thank you for installing Robusta 0.10.25 As an open source project, we collect general usage statistics. This data is extremely limited and contains only general metadata to help us understand usage patterns. If you are willing to share additional data, please do so! It really help us improve Robusta. You can set sendAdditionalTelemetry: true as a Helm value to send exception reports and additional data. This is disabled by default. To opt-out of telemetry entirely, set a ENABLE_TELEMETRY=false environment variable on the robusta-runner deployment. Visit the web UI at: https://platform.robusta.dev/
처음 설치하면 시스템 Sync 관련 작업이 필요하여 약 5분 정도 추가 시간이 소요됩니다. 아래 로그 메시지를 확인하여 Sync가 완료되었는지 확인합니다.
k stern robusta (생략) robusta-forwarder-54664c994c-xtvwc kubewatch time="2023-12-04T09:15:23Z" level=info msg="Message successfully sent to http://robusta-runner:80/api/handle at 2023-12-04 09:15:23.220129534 +0000 UTC m=+80.076064545 " robusta-forwarder-54664c994c-xtvwc kubewatch time="2023-12-04T09:15:23Z" level=info msg="Message successfully sent to http://robusta-runner:80/api/handle at 2023-12-04 09:15:23.221390076 +0000 UTC m=+80.077325097
robusta 관련 아래 파드가 정상 실행됩니다.
(baas-dev-01:monitoring)~$ kubectl get pod --selector 'app in (robusta-forwarder,robusta-runner)' NAME READY STATUS RESTARTS AGE robusta-forwarder-7df7d89447-twcqv 1/1 Running 0 5m51s robusta-runner-7d4d7dfbc4-9mxsl 1/1 Running 0 5m51s
참고로 2개의 파드를 선택하려면 위와 같이 selector 옵션을 app in (A, B)으로 실행합니다.
이제 robusta 알림 메시지를 받을 슬랙 채널 설정을 합니다. 새로운 슬랙 채널을 만들고 해당 채널의 webhook url을 설정합니다.
이 후 슬랙에서 ‘Add apps’ 설정을 추가합니다. Apps 메뉴에서 ‘Incoming WebHooks’를 선택하고 위에서 생성한 채널 이름을 선택합니다.
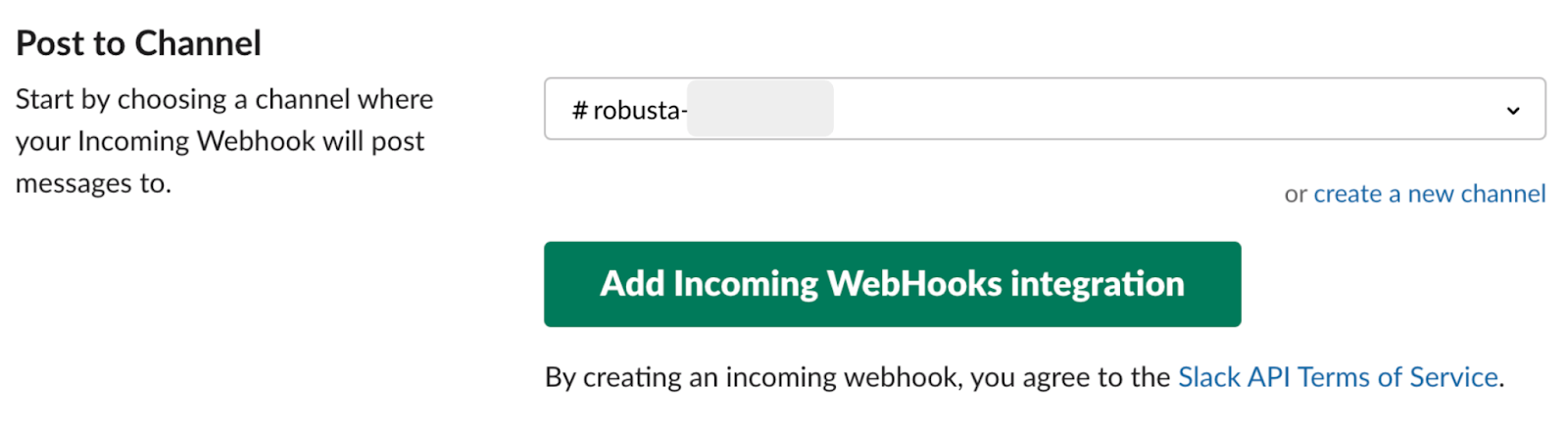
위 웹훅 설정은 아래의 Robusta 슬랙 설치 시 사용합니다.
명령창에 아래의 ‘robusta integrations slack’를 입력합니다.
(jerry-test:monitoring)robusta$ robusta integrations slack
If your browser does not automatically launch, open the below url:
새로운 브라우저가 열리면서 슬랙의 워크 스페이스를 선택하는 화면이 실행됩니다. 해당 화면에서 Rubusta가 메시지를 전송할 채널이 포함된 워크스페이스를 선택합니다. 선택이 완료되면 아래의 슬랙 ID와 Slack key를 확인할 수 있습니다. 필자는 보안 상 해당 메시지를 마스킹 처리하였습니다.
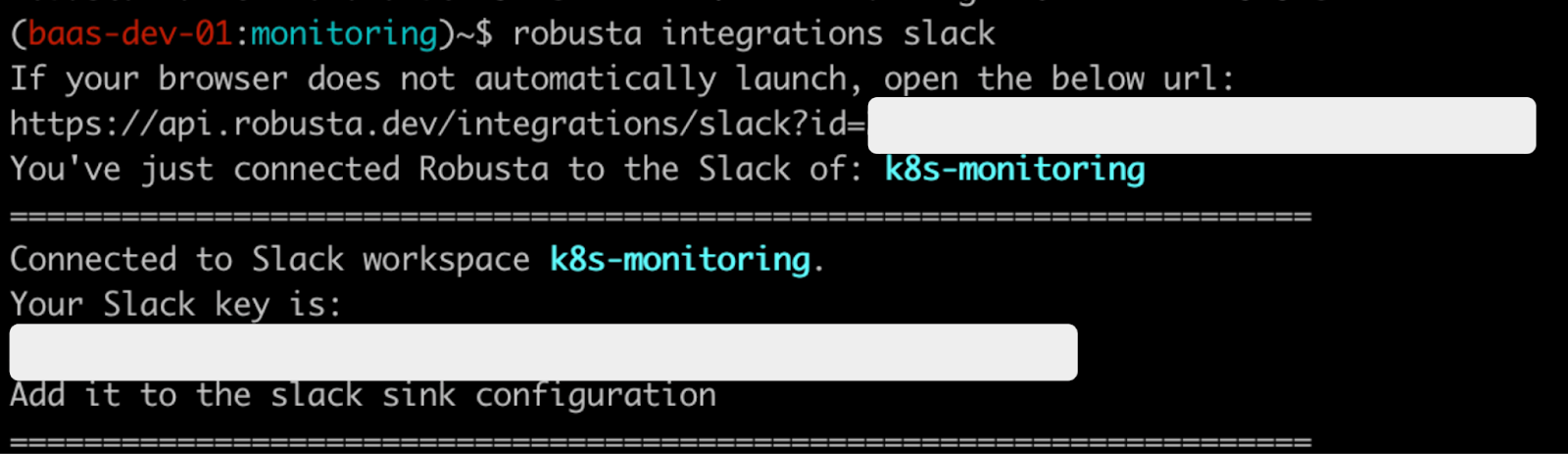
이제 기존에 생성한 Robusta 헬름 설정 파일(~/generated_values.yaml)에 아래의 슬랙 관련 설정을 추가합니다.
sinksConfig:
# slack integration params
- slack_sink:
name: main_slack_sink
api_key: MY SLACK KEY
slack_channel: MY SLACK CHANNEL
MY SLACK KEY 와 MY SLACK CHANNEL 정보는 각자 설정에 맞게 변경합니다. 헬름 업그레이드 작업을 진행하기 전 먼저 설정에 이상이 없는지 ‘helm diff’ 명령어를 이용하여 확인합니다.
(baas-dev-01:monitoring)robusta-0.10.25$ helm diff upgrade robusta -f ~/generated_values.yaml --set clusterName=baas-dev-01 .
monitoring, robusta-playbooks-config-secret, Secret (v1) has changed:
# Source: robusta/templates/playbooks-config.yaml
apiVersion: v1
kind: Secret
metadata:
name: robusta-playbooks-config-secret
namespace: monitoring
data:
- active_playbooks.yaml: '-------- # (10409 bytes)'
+ active_playbooks.yaml: '++++++++ # (10559 bytes)'
type: Opaque
정상적으로 설정 관련 ‘Secret’ 정보가 업데이트 됩니다. 업그레이드 작업을 진행합니다.
(baas-dev-01:monitoring)robusta-0.10.25$ helm upgrade robusta -f ~/generated_values.yaml --set clusterName=baas-dev-01 . Release "robusta" has been upgraded. Happy Helming! (생략) Visit the web UI at: https://platform.robusta.dev/
자, 이제 설정이 완료되었습니다.
임의로 에러가 있는 파드를 실행하여 정상적으로 에러 메시지가 슬랙으로 전송되는지 확인하겠습니다. Robusta에서 제공하는 샘플 파드를 사용합니다.
(baas-dev-01:monitoring)~$ k ns default (baas-dev-01:monitoring)~$ kubectl apply -f https://gist.githubusercontent.com/robusta-lab/283609047306dc1f05cf59806ade30b6/raw
‘CrashLoopBackOff’ 상태의 파드가 실행됩니다.
(baas-dev-01:default)~$ k get pod --selector app=crashpod NAME READY STATUS RESTARTS AGE crashpod-5794b8d86c-258xc 0/1 CrashLoopBackOff 2 (17s ago) 31s
슬랙에서 확인하면 아래와 같이 장애 메시지를 확인할 수 있습니다.
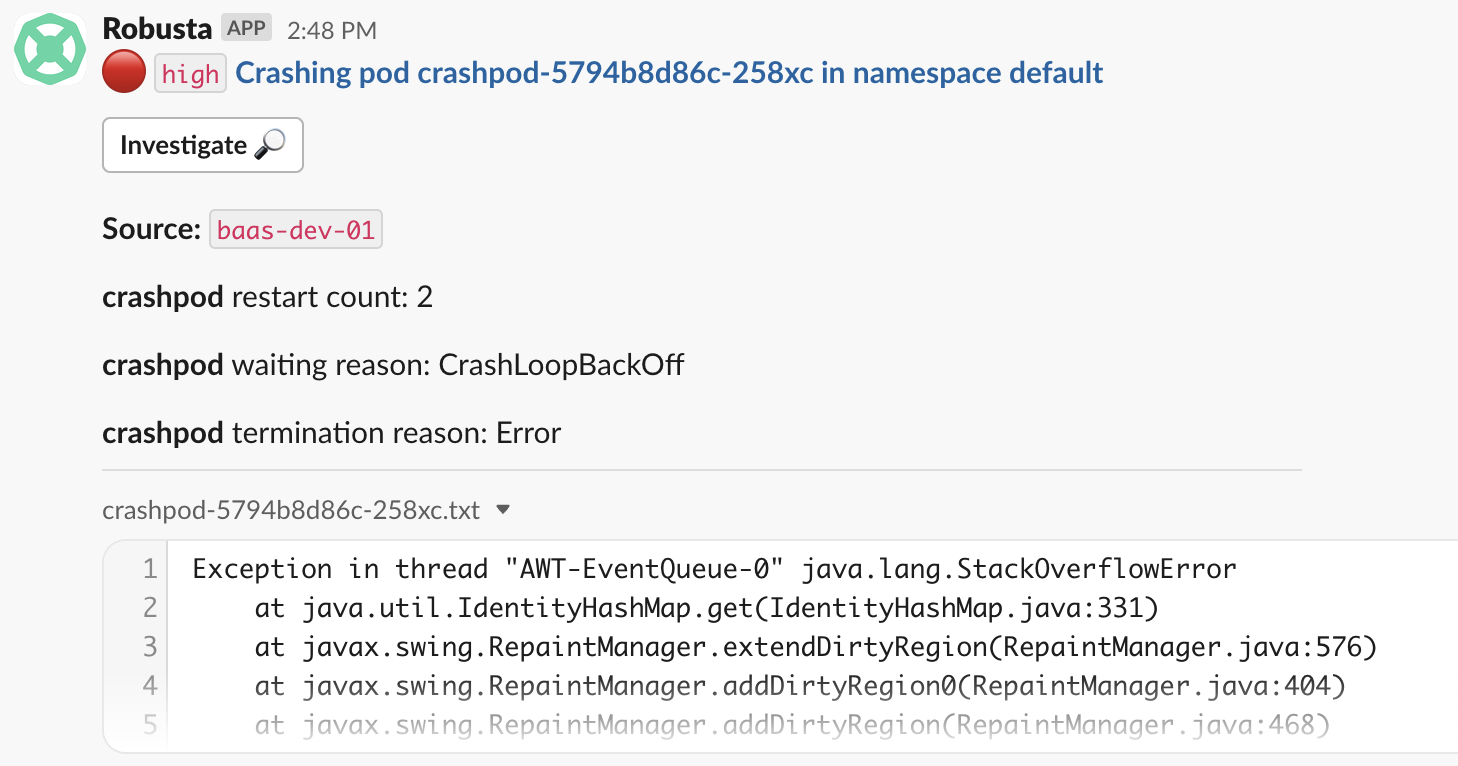
이전 AlertManager에 비하여 메시지가 훨씬 직관적이라 메시지를 확인하면 바로 ‘CrashLoopBackOff’ 에러임을 확인할 수 있습니다. 해당 메시지를 통하여 담당자는 좀 더 빠르게 장애 처리가 가능합니다.
Robusta는 다양한 장애 예제를 깃허브를 통해서 제공합니다. 아래 사이트에서 다양한 예제를 검증해 볼 수 있습니다.
https://github.com/robusta-dev/kubernetes-demos

Robusta는 추가로 모니터링 SaaS 서비스도 제공합니다. 아래 사이트에 접속하면 좀 더 편리한 UI를 확인할 수 있습니다.
https://platform.robusta.dev
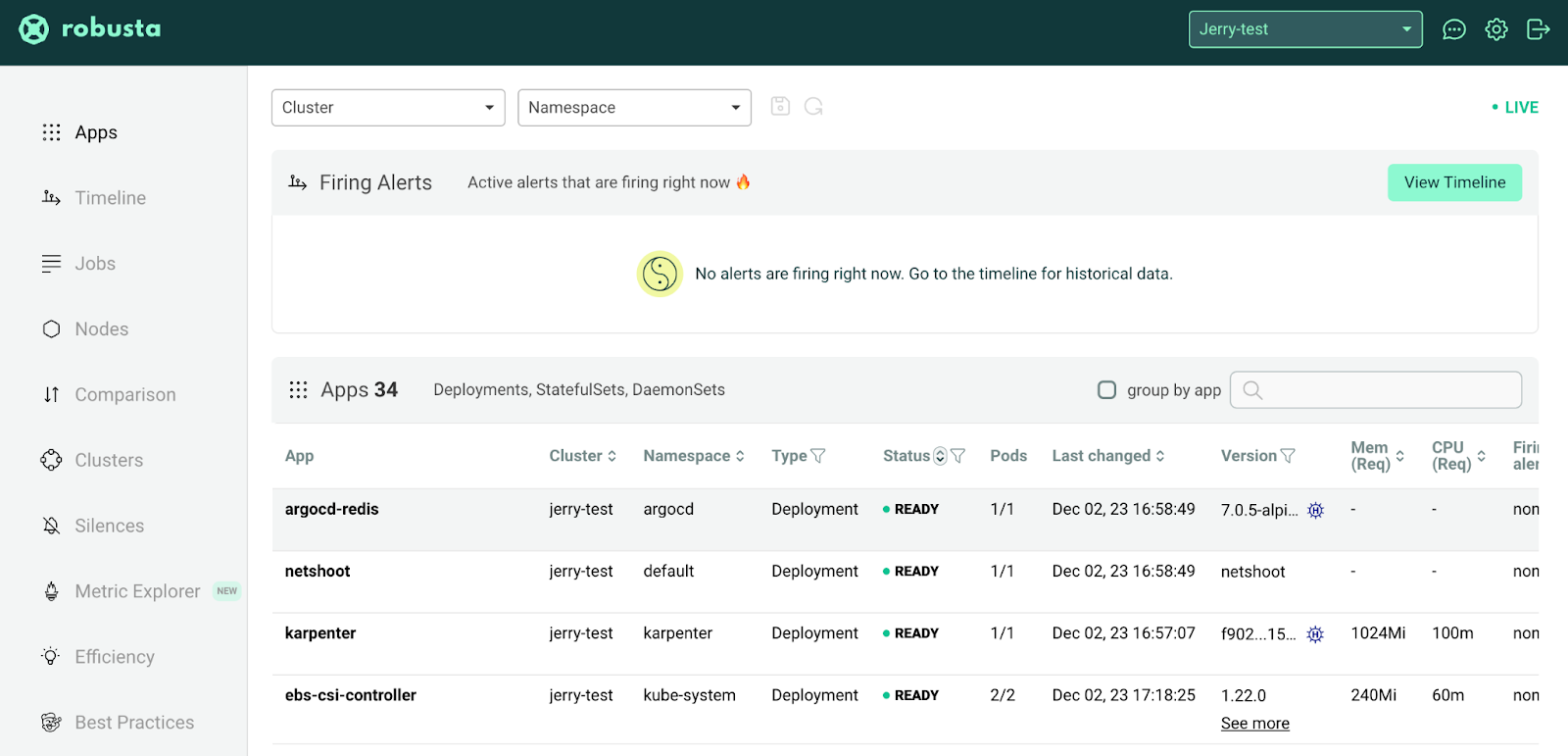
특히 화면 왼편의 ‘Timeline’ 메뉴를 확인하면 아래와 같이 시간대 별 장애 현황을 확인할 수 있어 매우 편리합니다.
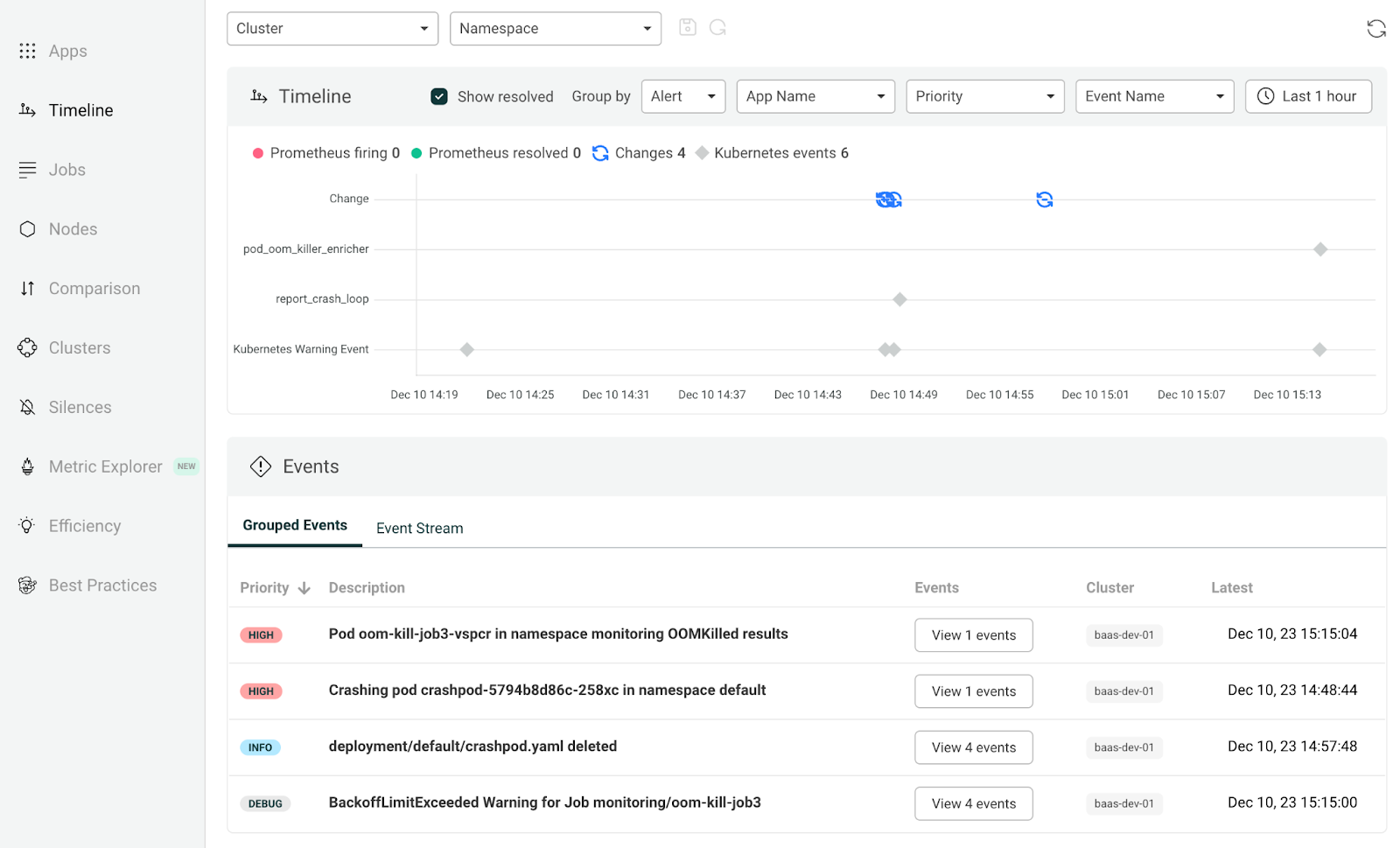
이렇게 Robusta를 이용하면 좀 더 직관적인 에러 알림을 받을 수 있어 편리합니다.
테스트를 완료하여 장애 파드를 제거합니다.
(baas-dev-01:default)~$ k delete deployments.apps crashpod deployment.apps "crashpod" deleted
7. 그라파나 알람 서비스 설정
운영 단계에서 애플리케이션에 관한 모니터링 대시보드는 그라파나에서 설정합니다. Redis, Kafka 등 퍼블릭 애플리케이션 이 외 회사에서 개발한 In-House 애플리케이션도 동일하게 대시보드를 만듭니다. CPU, 메모리 등 자원 사용량 뿐만 아니라 커넥션 숫자 등 구글의 4 Golden Signal 정보를 포함하는 것을 권고합니다.
해당 대시보드에 대한 알람은 그라파나에서 직접 설정할 수 있습니다. 그럼, 그라파나에서 알람을 설정하는 방법을 알아보겠습니다. 먼저 그라파나의 알람 관련 메뉴는 아래와 같이 화면 왼편에 있습니다.
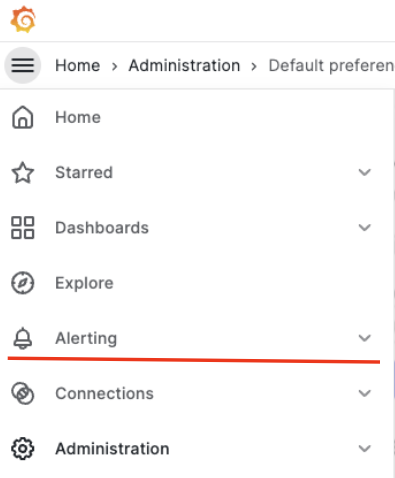
필자가 사용한 그라파나 버전은 23년 12월 기준 최신 버전인 10.0.3 입니다. 버전에 따라 메뉴는 달라질 수 있습니다.
(jerry-test:monitoring)~$ k describe pod prometheus-grafana-6fbc8d9774-7w58z
(생략)
Image: docker.io/grafana/grafana:10.0.3
해당 메뉴에서 알람 관련 설정을 진행합니다.
먼저 알람을 받을 채널, 즉 슬랙, 팀즈, 이메일 등을 설정합니다. ‘Alerting’ – ‘Contact Points’ 메뉴를 선택합니다.
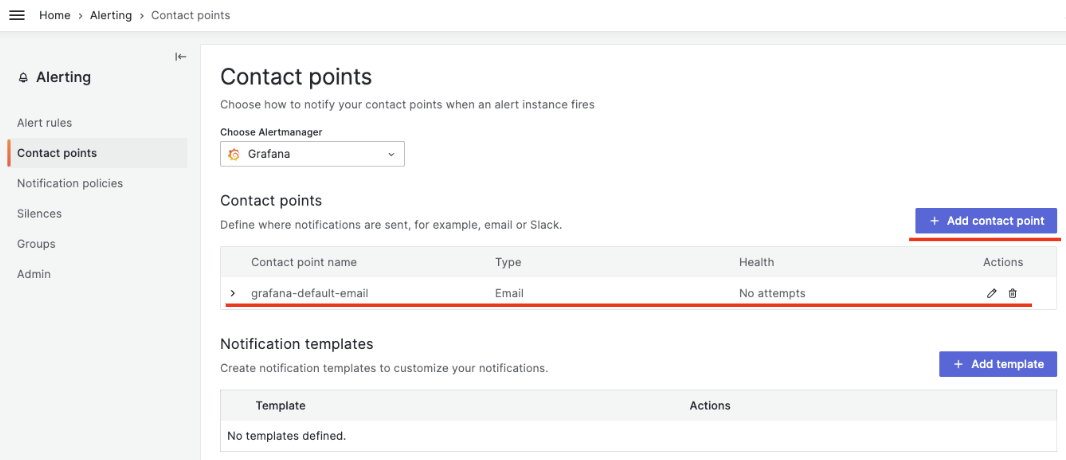
기본으로 위와 같이 ‘grafana-default-email’ 설정되어 있습니다. 필자는 이메일을 대신하여 슬랙을 사용합니다. 상단의 ‘Add contact point’ 메뉴를 선택합니다.
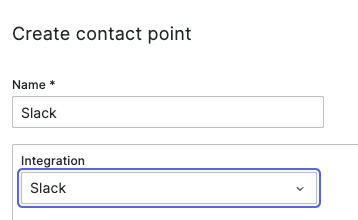
그라파나는 채널을 편리하게 통합할 수 있도록 다양한 채널 템플릿을 제공하고 있습니다. 슬랙의 경우 ‘Webhook URL’만 입력하면 간단히 설정이 완료됩니다.
알람을 받을 슬랙 채널 이름은 임의로 정하고 해당 슬랙 채널에서 ‘Webhook URL’을 아래와 같이 입력합니다. 민감한 정보라 필자는 마스킹 처리 하였습니다.
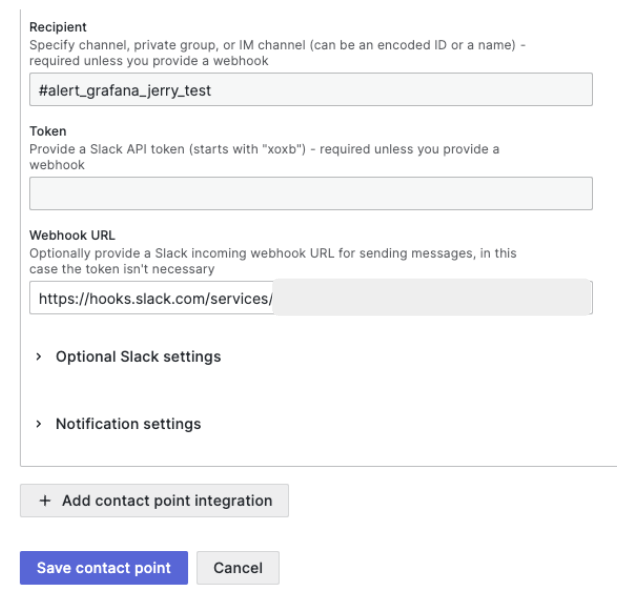
‘Webhook URL’은 슬랙에서 설정합니다. 슬랙 메뉴의 ‘Add apps’를 선택합니다.
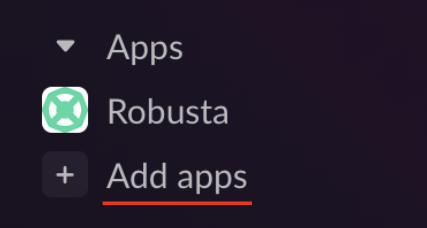
이어지는 화면에서 ‘Incoming WebHooks’를 선택합니다.
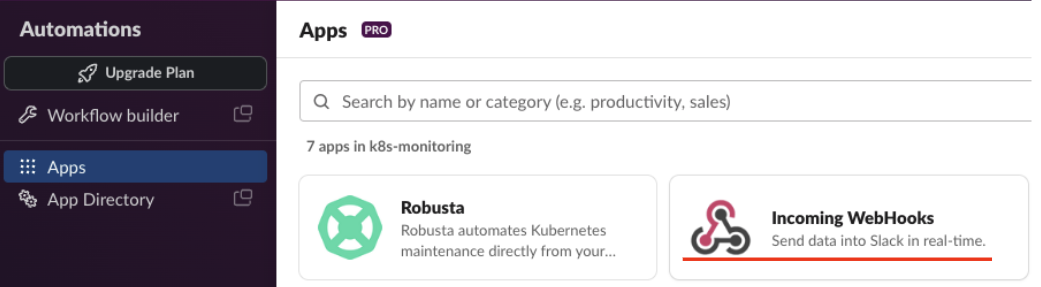
아래 ‘Configuration’ 메뉴를 선택하면 새로운 페이지로 연결됩니다.
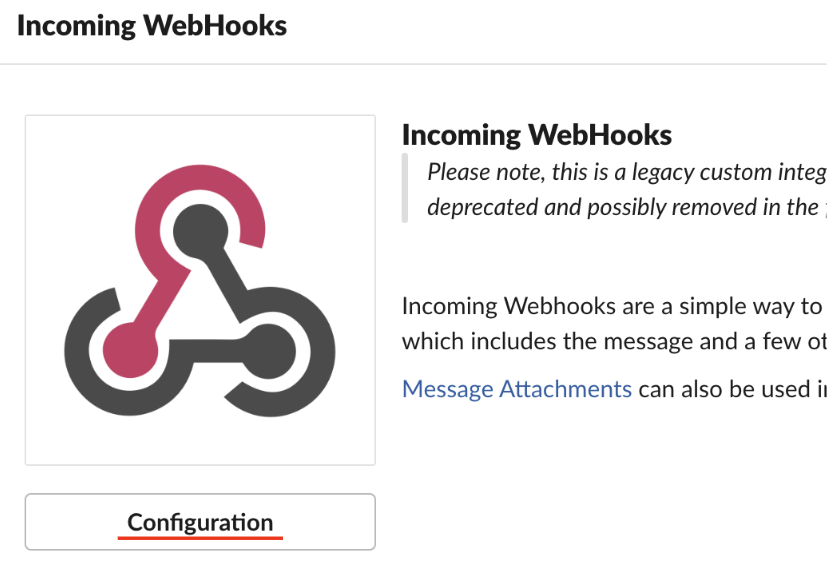
해당 페이지에서 그라파나 슬랙 알람을 받을 채널 이름을 지정합니다.
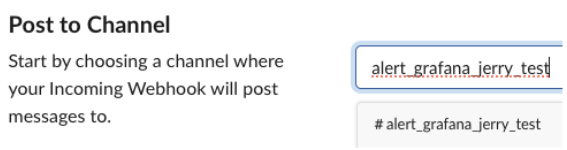
이제 ‘Webhook URL’을 확인할 수 있습니다.

해당 URL을 위 그라파나 ‘Contact points’ 메뉴에 입력합니다.
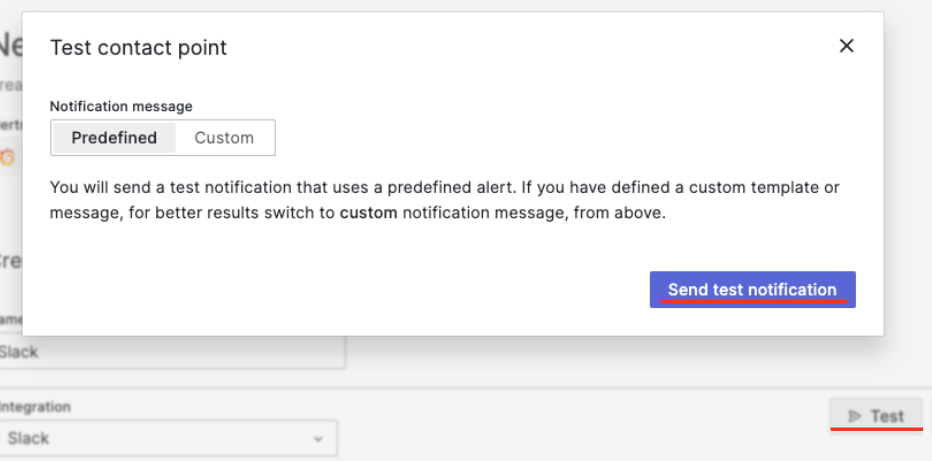
다시 그라파나로 돌아가 ‘Webhook URL’이 정상으로 설정되었는지는 ‘Test’ 메뉴에서 확인할 수 있습니다.
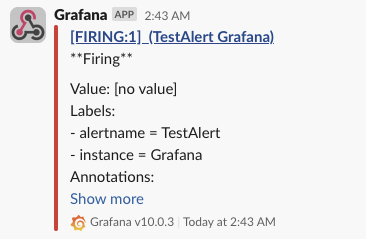
아래와 같이 메시지가 전송되면 슬랙 설정은 정상으로 완료되었습니다.
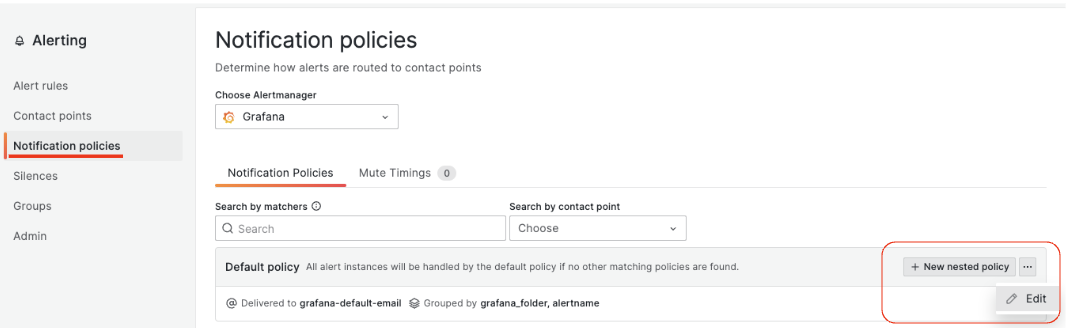
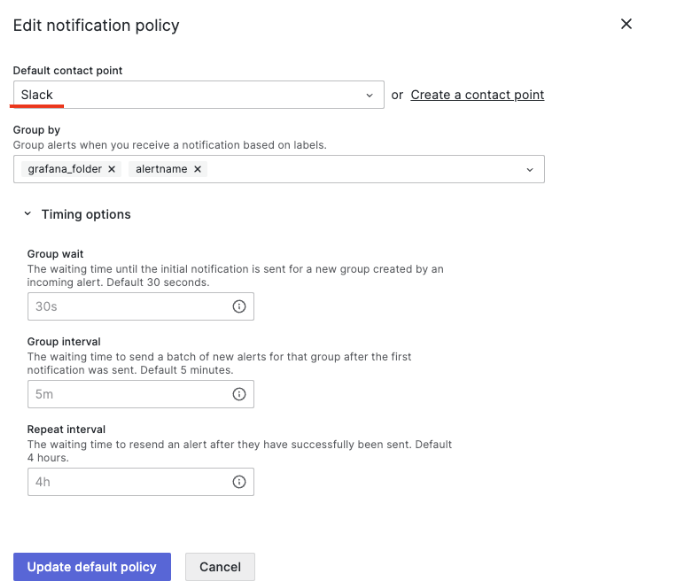
다음으로 그라파나에서 발생하는 알람이 슬랙으로 전송되도록 그라파나 알람의 기본 설정을 변경합니다. ‘Notification policies’ 메뉴에서 설정합니다. 화면 왼쪽의 ‘…’ 메뉴의 ‘Edit’을 선택합니다.
아래 ‘Default contact point’를 새롭게 생성한 채널 ‘Slack’으로 변경합니다.
이제 테스트 알람을 설정하여 슬랙으로 정상으로 알람이 전송되는지 확인하겠습니다. 테스트 알람은 임의로 설정할 수 있습니다. 필자는 CPU 사용률을 사용합니다. 테스트 알람은 애플리케이션 대시보드를 만들었다면 해당 대시보드를 기준으로 만드는 것이 좀 더 실제 상황과 유사합니다.
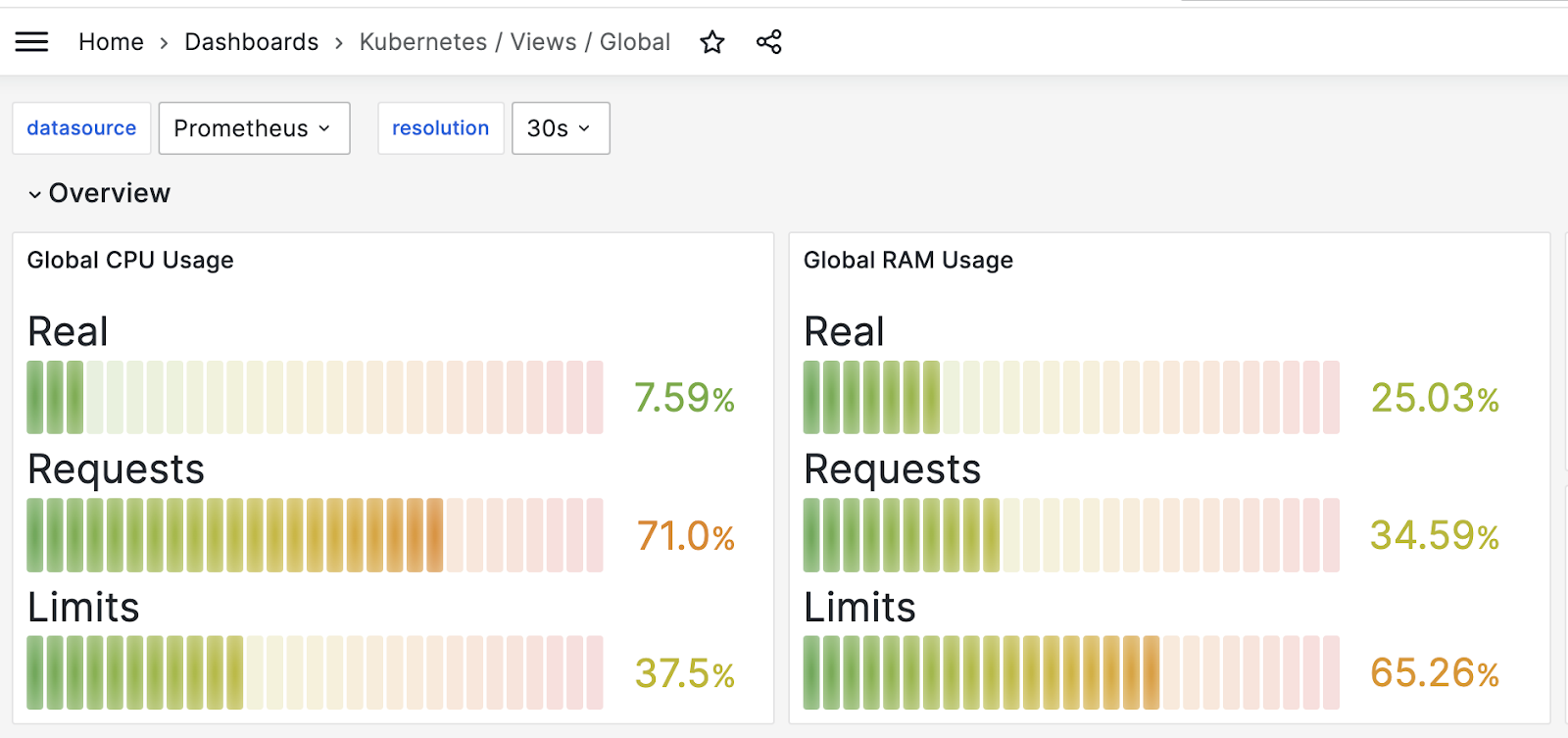
그라파나의 알람 설정은 대시보드에서 바로 설정할 수 있습니다. 알람 설정을 원하는 대시보드를 선택합니다. 필자는 앞에서 설치한 ‘Kubernetes / Views / Global’ 대시보드를 선택하였습니다.
‘Kubernetes / Views / Global’ 대시보드 화면
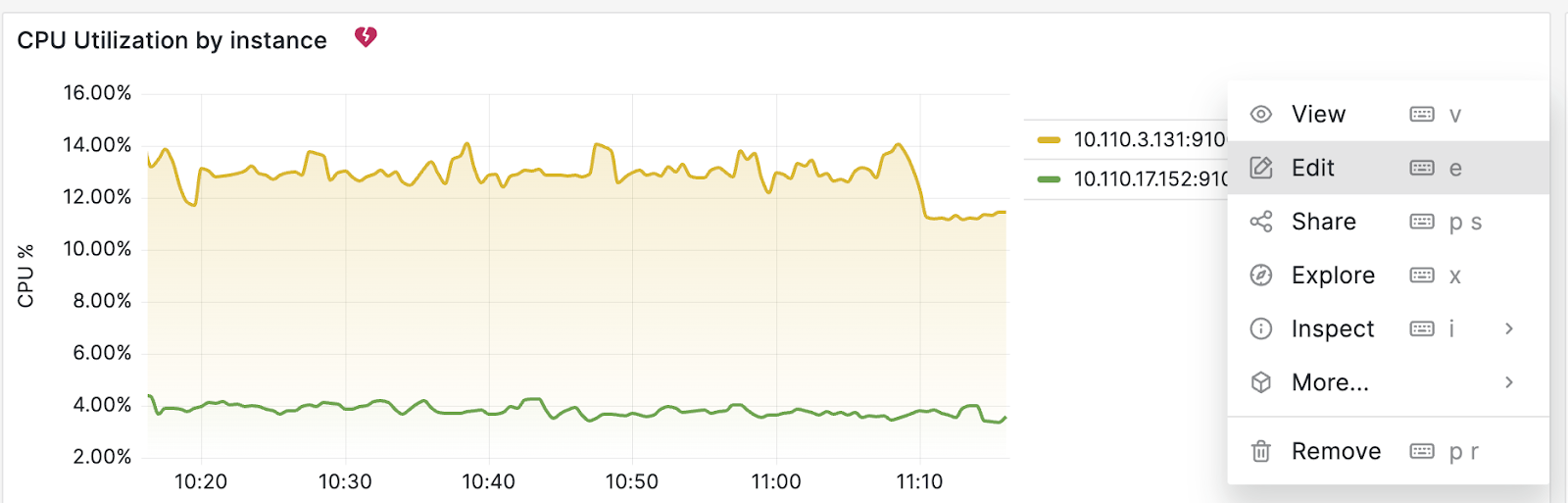
해당 대시보드에서 각 노드 별 CPU 사용률은 아래의 ‘CPU Utilization by instance’ 패널입니다. 알람 설정을 위하여 오른쪽 상단의 메뉴 – ‘Edit’ 를 선택합니다.
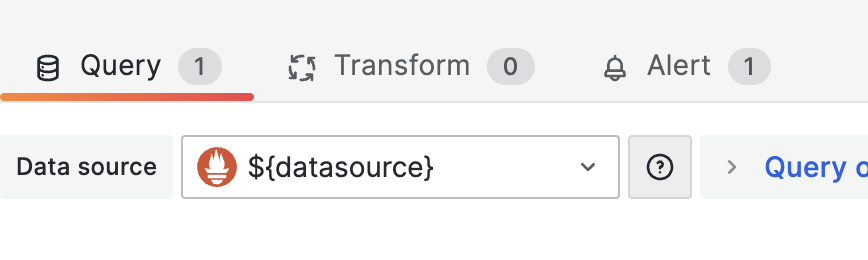
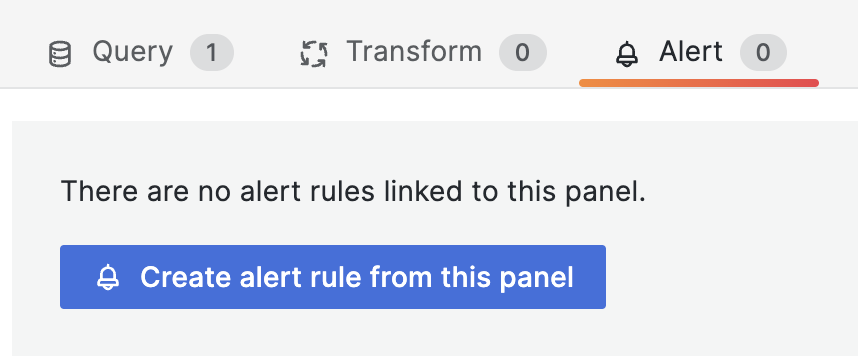
이어지는 화면에서 ‘Alert’를 선택합니다. 그리고 ‘Create alert rule from this panel’ 메뉴를 선택합니다.
이어지는 화면에서 알럿 관련 설정을 가이드에 따라 진행합니다. 먼저, 알람 이름을 임의로 설정합니다. 필자는 CPU 사용률이 5% 이하이면 알람을 받을 예정이라 아래와 같이 ‘Low CPU Utilization – 5%’로 지정하였습니다.

5% 이하인 경우 알람을 받기 위해서 먼저 B 항목에 ‘Threshold’ 선택하고 ‘IS BELOW’ ‘0.05’를 입력합니다. 임계값을 기준으로 알람 설정 예정이므로 ‘Threshold’ 이고 0.05는 5%를 의미합니다.
다음으로 C 항목에 ‘Reduce’의 Max 옵션을 선택합니다. 최대 사용률이 5% 미만인 경우 알람을 받도록 설정합니다. Input은 ‘B’ 즉 앞에서 설정한 ‘Threshold’ 값을 지정합니다.

설정을 완료하고 ‘Preview’ 버튼을 선택하면 현재 설정을 그래프와 ‘Firing’, ‘Normal’로 확인할 수 있습니다. 위 설정 기준으로 ‘10.110.17.152’ 노드가 5% 미만의 사용률이므로 정상적으로 ‘Firing’ 상태가 된 것을 확인할 수 있습니다.
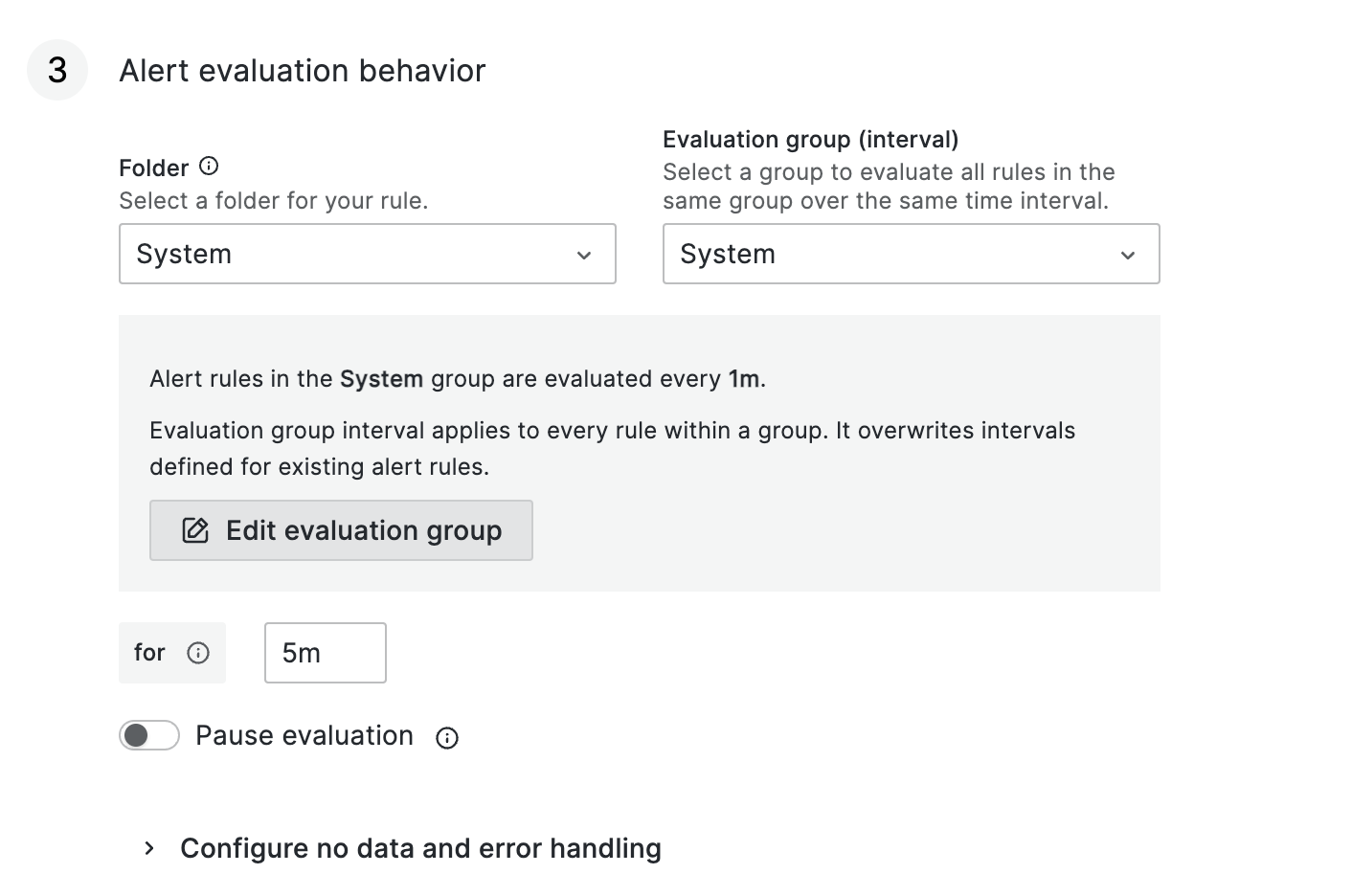
다음은 알람 확인 주기 입니다. 몇 분 간격(evaluation)으로 얼마나(for) 지속되면 알람을 보낼 것인지 설정합니다. 필자는 아래와 같이 1분 간격으로 5분 동안 지속되면 알람을 보내도록 설정하였습니다.
설정이 완료되면 화면 상단의 ‘Save rule and exit’를 눌러 저장합니다.
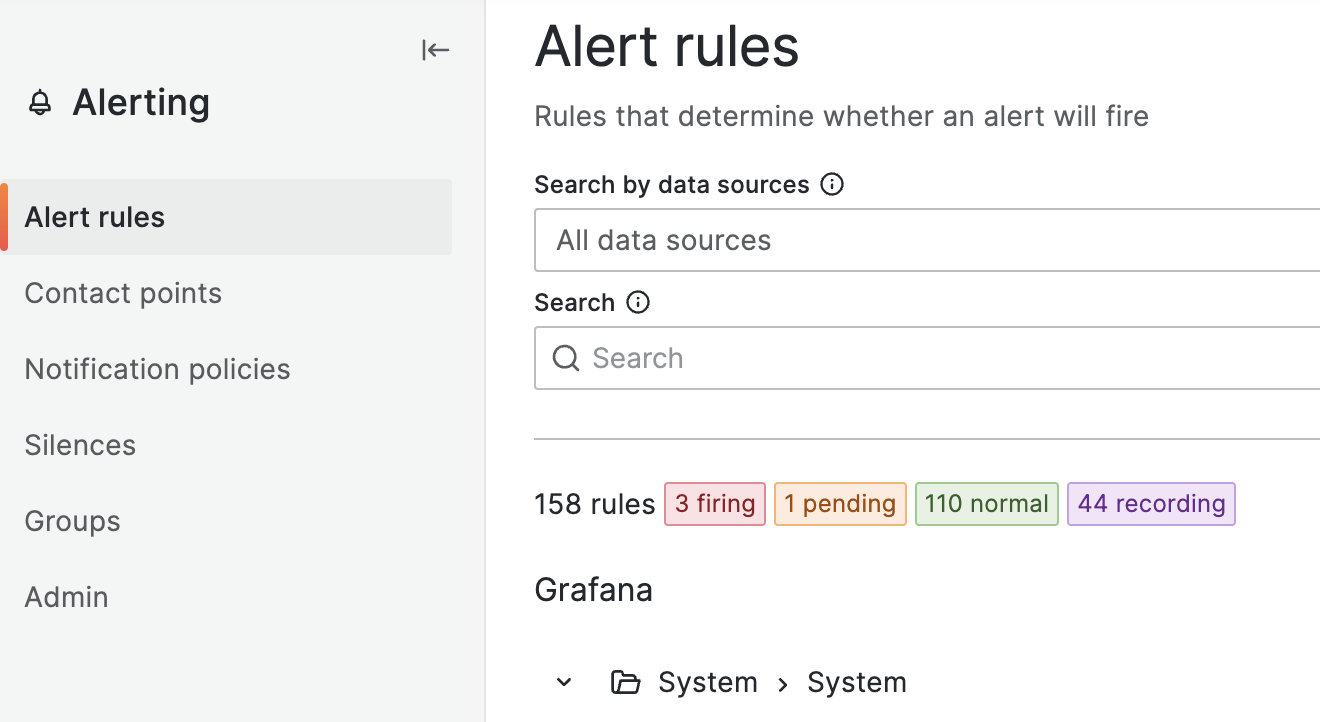
이제 Alert 메인 화면에서 아래와 같이 방금 설정한 ‘System > System’ 알람을 확인할 수 있습니다.
하나의 노드의 CPU 사용률이 5% 미만이라 아래와 같이 ‘Pending’ 상태를 확인할 수 있습니다. 설정한 5분 이상 지속되면 ‘Firing’ 상태로 변경되고 알람이 전달됩니다.

5분이 지나면 아래와 같이 슬랙에서 메시지를 확인할 수 있습니다.
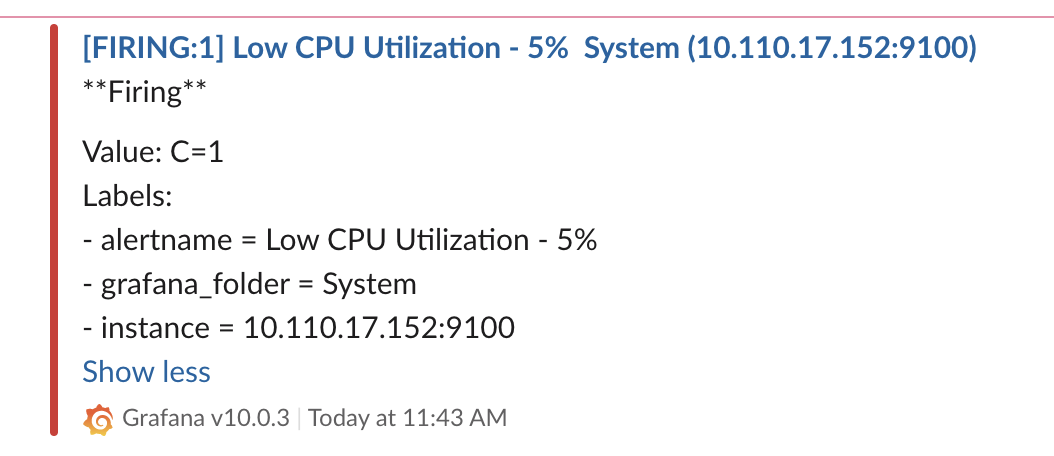
이상 그라파나에서 알럿 설정을 설정하는 방법을 확인하였습니다. 실제 운영 환경에서 각 서비스 별 대시보드를 생성하는데 해당 대시보드에서 필요한 알람을 위와 같이 바로 설정할 수 있습니다.
이번 글에서 쿠버네티스 알람 시스템에 관하여 알아보았습니다. 먼저, 알람 시스템은 어떠한 요구 사항을 만족해야 하는지 이러한 요구 사항을 만족하기 위하여 Alertmanager, Robusta, 그라파나 통해서 어떻게 구현할 수 있는지를 실습으로 알아보았습니다.
해당 기술 블로그에 질문이 있으시면 언제든지 문의해 주세요. 직접 답변해 드립니다.
k8sqna@jennifersoft.com
1.필자는 Naming Convention도 아주 중요한 업무라 생각합니다. 이름은 한번 생성하면 자주 불리므로 의미를 가지는 것이 중요합니다.
2.설치 가이드 https://docs.robusta.dev/master/setup-robusta/installation/extend-prometheus-installation.html
3. SOPS https://github.com/getsops/sops
