스택트레이스 샘플링을 이용한 성능 분석 – SFR(Stacktrace Flight Recorder)

지난 https://jennifersoft.com/ko/blog/tech/2021-10-18/ 에 소개된 개별 트랜잭션을 대상으로 한 스택트레이스 분석 기능을 이용한 Jira 의 성능 개선 후 그 동안 Jira 는 한 번의 재시작 없이 여전히 빠른 응답시간을 유지하고 있습니다. (그래서 Jira 의 최신 버전을 써볼 수 없다는 점은 조금 아쉽습니다. ㅎ)
이번에는 전체 애플리케이션 성능 분석에 도움이 될 수 있는 기능을 가지고 돌아왔습니다.
개별 트랜잭션 분석으로는 개선이 불가능한 성능 이슈를 해결하기 위한 개발자 Y의 고분 군투기.
지금 시작합니다!
프롤로그
여느때와 다름없이 평화로운 어느날. 개발자 Y는 여전히 APM 의 수집서버 업무를 담당하고 있었습니다.
그런데 최근 비슷한 유형의 이슈들이 Jira 에 등록되고 있는것을 확인합니다.
수집서버의 로그에 다음과 같은 내용이 출력되면서 대시보드에 데이터 표시되지 않는다고 합니다!
server.data.2022-04-14.log:2022-04-14 15:33:04.833 KST [:ME:CommandFromViewServerProcessor] WARN c.a.d.n.CommandFromViewServerHandler - Request from view takes much time to finish. request=CommandRequest(key=520:70,bodyLength=94), finish=350/1000, wait=0, process=350<br> server.data.2022-04-14.log:2022-04-14 15:33:04.990 KST [:ME:CommandFromViewServerProcessor] WARN c.a.d.n.CommandFromViewServerHandler - Request from view takes much time to finish. request=CommandRequest(key=520:70,bodyLength=94), finish=300/1000, wait=0, process=300<br> server.data.2022-04-14.log:2022-04-14 15:33:08.186 KST [:ME:CommandFromViewServerProcessor] WARN c.a.d.n.CommandFromViewServerHandler - Request from view takes much time to finish. request=CommandRequest(key=520:70,bodyLength=136), finish=401/1000, wait=0, process=401<br> server.data.2022-04-14.log:2022-04-14 15:33:08.701 KST [:ME:CommandFromViewServerProcessor] WARN c.a.d.n.CommandFromViewServerHandler - Request from view takes much time to finish. request=CommandRequest(key=520:70,bodyLength=136), finish=294/1000, wait=0, process=294<br> server.data.2022-04-14.log:2022-04-14 16:28:02.497 KST [:ME:CommandFromViewServerProcessor] WARN c.a.d.n.CommandFromViewServerHandler - Request from view takes much time to finish. request=CommandRequest(key=520:70,bodyLength=94), finish=300/1000, wait=0, process=300
간단히 내용을 파악해보면 각 요청은 1초 안에 처리가 끝나야 하는데 개별 처리가 0.2 초에서 0.4 초까지 소요된다는 내용입니다.
잠깐.. 1초도 아닌 0.x 초의 요청에 대한 성능 개선을 해야 한다니 가능한 것일까요?
저번에 사용한 트랜잭션 단위로 수집된 스택트레이스 분석 기능을 이용해보기로 합니다.
일단 X-View챠트를 확인해 봅니다.
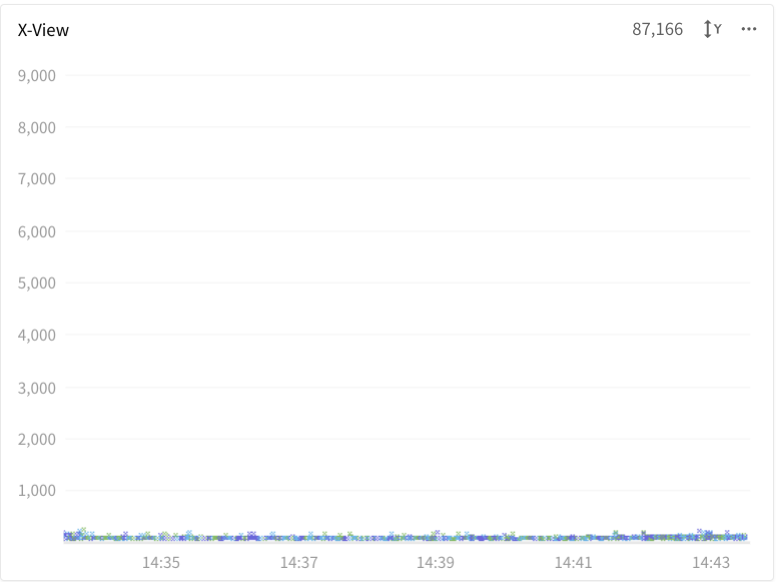
대다수의 트랜잭션이 1초도 되지 않는 시간에 처리되고 있네요.
XView 차트의 Y축을 더 작은 시간으로 조절해서 그나마 스택트레이스 수집된 트랜잭션을 발견했습니다.
이 수집서버는 웹 요청이 아닌 TCP 요청을 처리하는 서버이기에 개별 트랜잭션의 매우 짧은 시간에 끝나는 특징을 갖고 있는 것을 확인할 수 있습니다.
하지만 트랜잭션당 한개씩 수집된 스택트레이스 정보로는 성능 개선에 대한 실마리를 잡을 수 없으니.. 어떻게 해야할지 막막하기만 합니다.
곰곰히 생각해보니 이전 담당하던 개발자가 메서드 호출을 샘플링하는 기능을 넣어두었던 것 같은데..? 얼른 옵션을 활성화해서 로그를 확인해 봅니다.
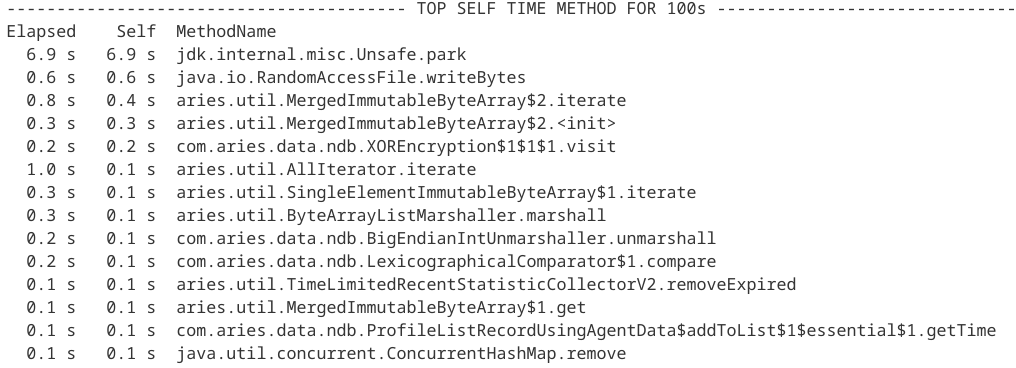
이 기능은 위 스크린샷과 같이 호출된 메서드의 샘플링 결과를 로그에 출력하는 형태를 띄고 있습니다.
왼쪽의 Elapsed, Self 에 표시된 숫자의 값이 큰 메서드가 빈번하게 혹은 오랫동안 수행된 녀석이 되는 것입니다. 유난히 눈에 띄는 메서드가 있기에 이 메서드를 호출한 부분을 찾아 수정하면 될 것 같습니다.
메서드의 호출 위치를 찾다보니 이런 생각이 듭니다.
“일일히 메서드의 위치를 찾는게 좀 번거로운데..”
“FlameGraph 로 보여주면 어딜 봐야할지 바로 찾을 수 있지 않을까?”
“예전에 분석했던 샘플링 결과는 텍스트로 남겨놔야 하니 찾기도 힘들고 기억도 안나고..”
“이런 분석 기능을 내 업무용으로만 쓰기 좀 아깝네. 메서드 성능 분석이 필요한 사용자도 쓸 수 있다면 더 좋을텐데.”
“좋아. 이것도 제니퍼의 기능으로 만들어보자!”
새로운 스택트레이스 분석 기능을 위한 준비
개별 트랜잭션이 아닌 애플리케이션 전체에 걸친 샘플링 결과를 조회해야 하기에 기존과 달리 X-View 팝업과 같은 진입점이 없기에 새로운 분석화면이 필요하게 되었습니다.
이 분석 기능에는 기존에 로그에 출력되던 샘플링 기능의 장점과 단점을 보완하기 위해 다음과 같은 목표를 세웠습니다.
- 최소 하루 이상의 범위에도 빠르게 조회가 가능할 것 (빨리빨리..)
- 별도의 복잡한 설정과정 없이 간단하게 이용할 수 있을 것 (개발자, 담당자는 귀찮은걸 싫어할거야..)
- 에이전트와 수집서버에 주는 영향도 최소화 (이거 쓴다고 장애가 발생하면 안되겠지?)
- 찾고자 하는 메서드의 호출 관계를 직관적으로 파악할 수 있을 것 (시간은 금이로다..)
최초로 필수 구성요소는 간단하게 두가지를 선정했습니다.
- 스택트레이스 수집 시점에 호출중이었던 메서드의 통계 (이후 Top 메서드 라고 부릅니다.)
- 조회 범위로부터 조회된 스택트레이스를 기반으로 한 FlameGraph
아.. 그런데 이전과 달리 분석의 대상이 되는 스택트레이스의 개수가 아주 많을 가능성이 있겠다는 생각이 듭니다. 이전에는 하나의 트랜잭션에 대한 스택트레이스 정보였다면 이제는 애플리케이션 전체에서 수집된 스택트레이스 정보이기 때문이죠.
“일전의 식상한 분 단위 조회시간 범위 조절 방법말고 더 나은 방법이 없을까?”
Y씨는 FlameGraph 와 관련된 기사들을 관심있게 살펴보다 FlameScope(https://netflixtechblog.com/netflix-flamescope-a57ca19d47bb) 라는 것을 발견합니다.
내용을 살펴보니 FlameGraph 를 고안한 개발자가 개발한 시각화 방법입니다.
간단하게 이야기 하면 히트맵 차트에 작은 단위의 시간 구간으로 집계한 데이터를 개수에 비례하는 색상의 진하기로 나타내는 차트입니다. 일반 히트맵과의 차이는 X, Y 축이 모두 시간을 표시하기에 시간의 흐름에 따른 패턴을 표현할 수 있다는 점입니다.
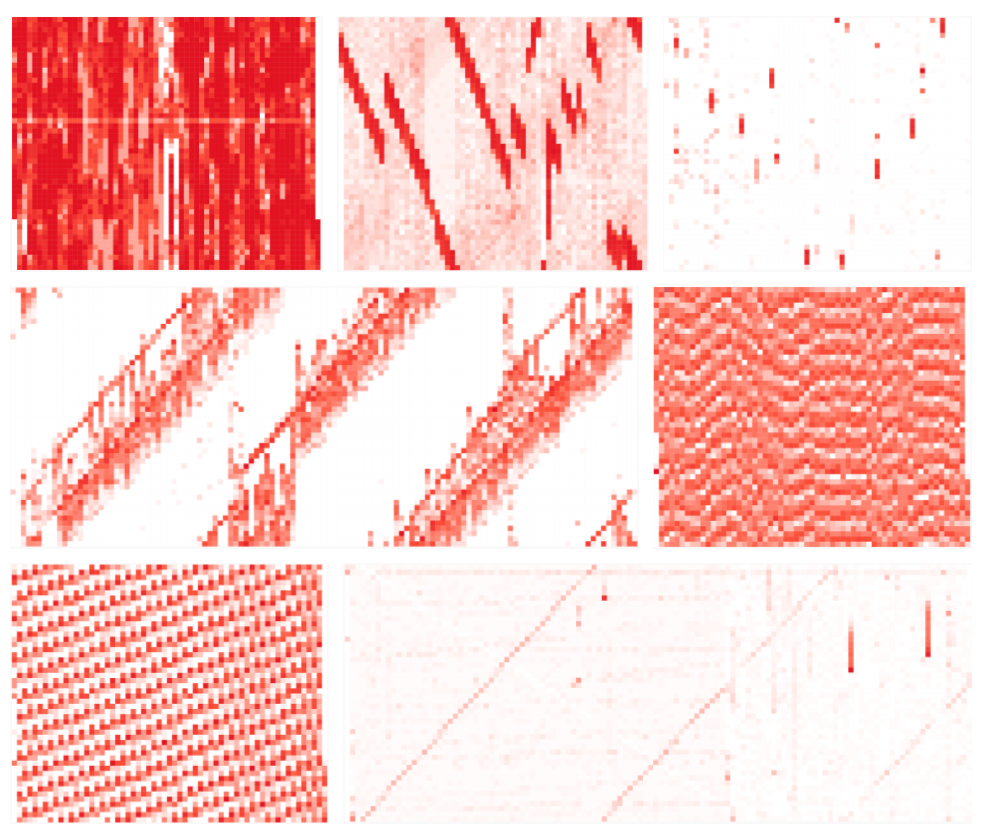
오호라.. 이것이라면 대량의 데이터를 조회하기 위한 범위 조절기로 쓸 수 있을 것 같습니다. 혹여나 저런 패턴을 보게 된다면 애플리케이션의 상태까지 덤으로 파악할 수 있겠죠?
이렇게 새로운 분석화면을 위한 3개의 항목이 선정 되었습니다.
패턴으로 애플리케이션의 상태를 알 수 있는 것 외에도 시간의 흐름을 나타내는 차트이기에 범위를 드래그 할 수 있고 대량의 스택트레이스 정보의 조회 범위를 설정할 수 있는 역할을 할 수 있습니다
- FlameScope
- Top Method
- FlameGraph
각 항목에 대한 자세한 내용은 분석 화면이 완성되면 하나 하나 자세히 소개해 드릴께요.
그로부터 약 3달 후..
프론트 개발자, 디자이너와 함께 치열한 토의를 거쳐 어느덧 새로운 분석 기능이 구현 되었습니다.
기능의 이름은 내부적으로 공모하여 투표로 진행했고 SFR(Stacktrace Flight Recorder) 로 결정 되었습니다. 애플리케이션이 동작하는 가운데 알게 모르게 점진적으로 스택트레이스 정보를 기록한다는 의미를 갖고 있습니다.
예상치 못한 상황이 있을때 상시 기록된 스택 정보로 원인 파악에 결정적인 도움이 될것이라 기대합니다.
SFR 을 소개합니다.
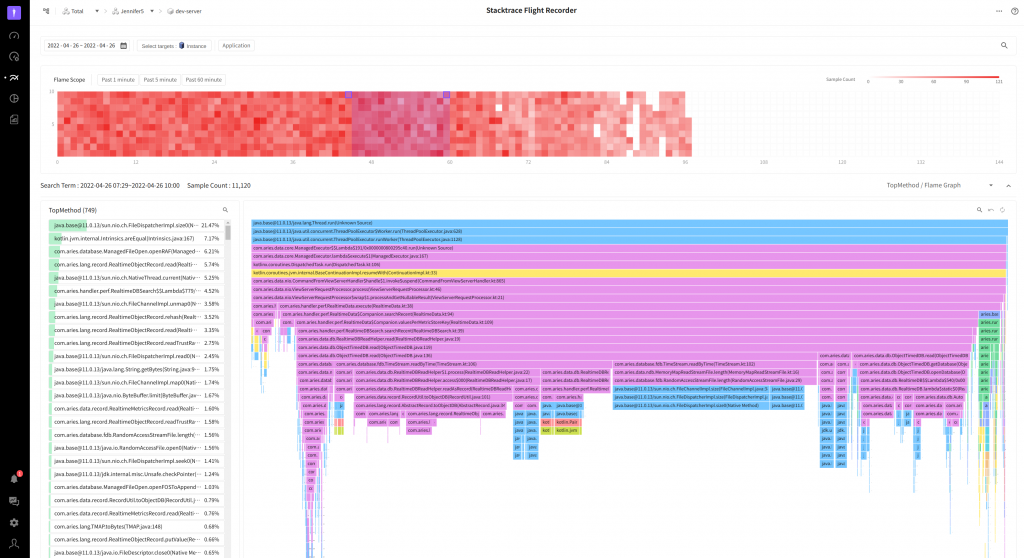
각 구성요소의 의도와 목적
위 첨부된 이미지와 같이 SFR 은 크게 3개의 구성요소로 이루어져 있습니다.
1.FlameScope

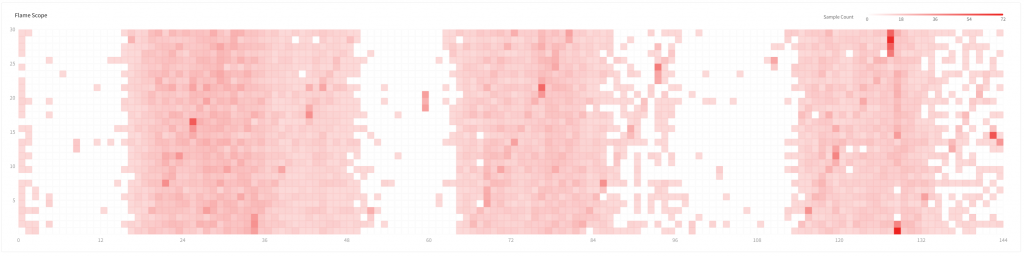
붉은색 계열을 갖는 작은 네모를 잔뜩 그린 차트입니다. 각 네모 한칸은 1분의 구간을 의미하며 수집된 스택트레이스의 개수가 많을수록 더 짙은 빨강색으로 표현됩니다.
FlameScope 는 크게 두가지 목적을 갖고 있습니다.
- TopMethod, FlameGraph 조회 범위 선택 일 단위로 넘어가는 범위로 조회했을때의 변화를 살펴보고 싶어 최대 조회기간은 7일로 정했습니다. 만약 이 기간에 속하는 데이터를 모두 조회한다면 느린 조회 속도로 사용자가 기대하는 사용성을 만족시킬 수 없겠죠? 더 붉은 부분은 어떤 이유로 인해 더 많은 스택트레이스가 수집 되었음을 뜻합니다. 일반적으로 사용자가 확인해야 할 부분은 바로 이 지점입니다. FlameScope 를 이용해 분단위 수집 빈도를 바탕으로 표시했기 때문에 사용자의 분석에 필요한 시간 구간대를 좁힐 수 있습니다. (프로파일을 확인하기 위한 X-View 차트와 유사한 관계입니다.)
- 히트맵 차트에 나타나는 패턴을 기반으로 애플리케이션의 특징, 상태 예측 위에서 FlameGraph 를 선정하게 된 과정에서 적었던 바와 같이 애플리케이션의 어떠한 상태를 보여줄 수 있습니다. 사내에서는 특정 시간에 부하가 집중되는 패턴, 시간 간격을 갖고 주기적으로 실행되는 일부 패턴을 확인할 수 있었습니다.

2 TopMethod
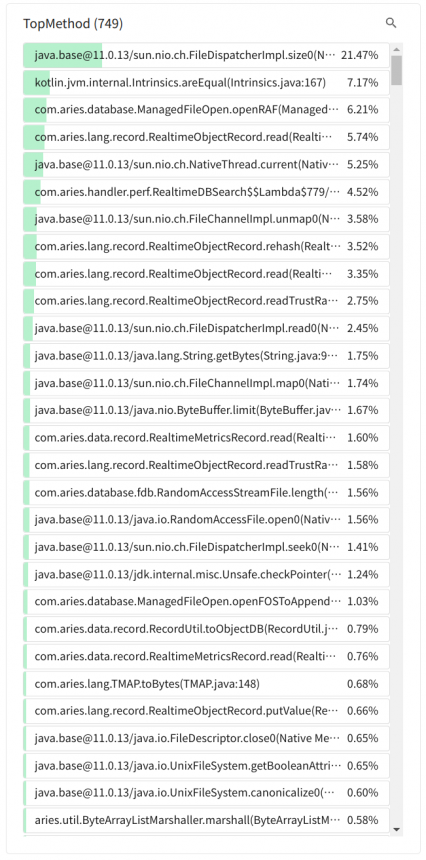
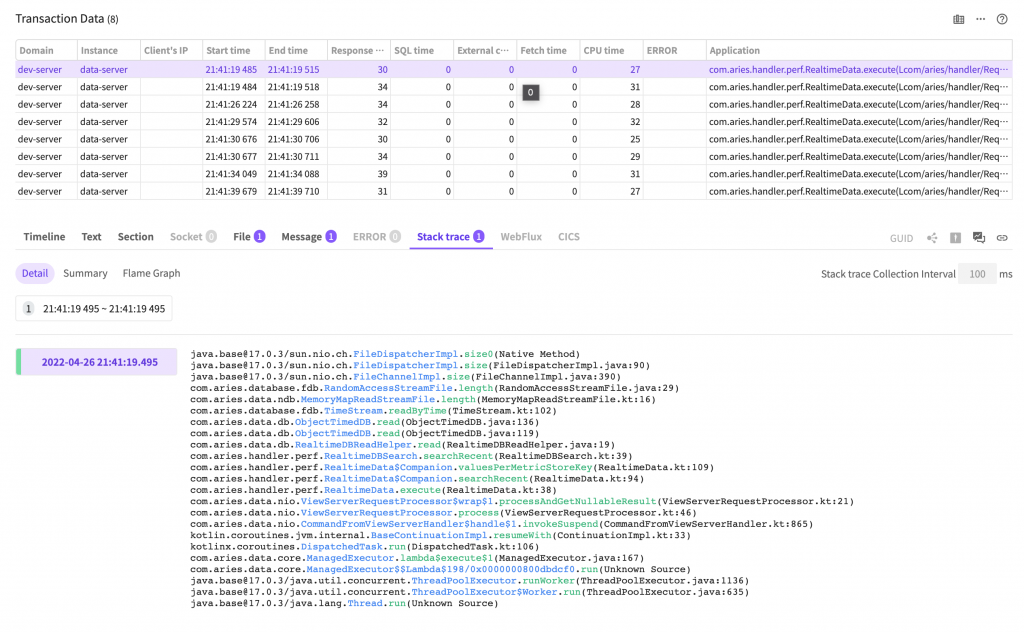
스택트레이스를 수집한 시점에 수행중이었던 메서드의 호출 분포를 나타냅니다.
이곳에 사용자가 만든 메서드가 위쪽에 위치한다면 바로 그메서드가 병목 지점일 가능성이 높습니다. 위 스크린샷에서는 파일의 크기를 측정하는 FileDispatcherImpl.size0 메서드가 가장 많은 빈도로 호출 되었습니다.
이전에 측정한 파일의 크기를 캐시하는 방법을 이용하면 이 메서드의 등장 빈도를 낮출 수 있고 그 시간동안 다른 메서드가 실행될 수 있는 시간을 확보하게 됩니다. 이것은 애플리케이션의 성능 향상으로 이어지게 될 것입니다.
과거 로그 기반의 메서드 샘플링 분석 기능을 이용할 때 가장 유용하게 사용 되었던 부분으로 여기에 나타난 메서드를 호출한 부분을 찾아 개선하는 과정을 반복합니다.
단, 한 가지 한계가 있었으니.. 여기에 나타난 메서드를 찾기 위해서는 IDE 를 이용해서 호출한 메서드 찾기에 상당량의 시간을 소비해야 했습니다. 만약 그 메서드가 여러 곳에서 호출되고 있는 경우에는 더욱 지루한 작업이 아닐 수 없겠죠? (IDE가 없다면 아마도 불가능했을거에요.)
3.FlameGraph

TopMethod 에서의 지루한 메서드 위치 찾기로부터 저를 해방시켜준 구원자 입니다. 😍 여기서는 기존과 달리 거꾸로 뒤집힌 형태의 FlameGraph 를 이용했습니다.
일반적으로 Inverted FlameGraph 혹은 Icicle Graph 로 불립니다. 위에서부터 아래로 서서히 작아지는 모습이 빙하의 모습을 띄고 있는 점에서 착안한 이름이라고 합니다. 그래프의 가장 위쪽은 스택트레이스의 시작지점, 아래로 갈수록 최근에 실행된 메서드가 표시됩니다.
만약 일반적인 형태의 FlameGraph 를 이용했다면 낮은 해상도의 모니터를 사용하는 사용자의 경우 높은 확률로 얇은 젓가락 구간들만 보게 될 것입니다. 이 기능을 처음 접한 사용자는 당황할지도 모릅니다. (심지어 이 경우는 메서드의 이름도 보이지 않습니다.)
Inverted FlameGraph 를 이용하면 적어도 상단에 보이는 영역은 호출 스택의 시작 지점이 되기에 사용자가 어느 정도 쉽게 인지할 가능성이 높다고 생각했습니다. 그리고 Self 메서드는 이미 왼쪽에 있는 TopMethod 에서 바로 확인이 가능한 상태입니다!
왼쪽에 위치한 TopMethod 의 각 라인을 클릭하거나 검색 키워드를 입력하면 해당 메서드의 위치를 FlameGraph 에 강조하여 표시해주기 때문에 자주 호출된 메서드와 그 메서드의 호출한 부분을 간단하게 확인할 수 있습니다.

지금까지 SFR 의 각 구성요소에 대해 알아보았습니다.
이제 SFR 을 이용해서 개발자 Y가 겪은 비교적 작은 응답시간을 갖는 애플리케이션의 성능 개선을 시도해보고 실제로 효과가 있는지 확인해볼까요?
무엇이 문제였을까?
APM 대시보드에 표시되는 각 차트의 데이터는 수집 대상별, 차트의 종류별로 1초마다 저장 됩니다. 따라서 모니터링 대상이 많아질수록 조회 속도는 느려질 수 밖에 없는데요.
사용자에게 적절한 개수의 모니터링 대상을 유지할 것을 권장하여도 이것을 강제할 수는 없습니다. 😅
개별의 조회는 아무리 빠르더라도 디스크 I/O 와 직결되어 있는 데이터 조회인만큼 병렬 조회 시도가 이루어지면 대부분의 스레드가 작업을 처리하는 상태가 되어 이후의 요청은 대기 상태가 됩니다.
2022-03-30 00:00:03.979 [:ME:CommandFromViewServerProcessor] WARN c.a.d.n.CommandFromViewServerHandler - Request from view takes much time to finish. request=CommandRequest(key=520:70,bodyLength=4258), finish=750/1000, wait=717, process=32 2022-03-30 00:00:04.002 [:ME:CommandFromViewServerProcessor] WARN c.a.d.n.CommandFromViewServerHandler - Request from view takes much time to finish. request=CommandRequest(key=520:70,bodyLength=2098), finish=783/1000, wait=717, process=65
처리 시간(process)은 얼마 되지 않지만 대기시간(wait) 이 상당히 큰 것을 알 수 있습니다. wait 을 줄이려면 각각의 작은 태스크의 처리 시간을 더욱 줄이면 됩니다
권장안을 지키지 않아도 어느 정도의 사용성은 보장해야 하기에 병목지점을 정확히 파악하고 응답시간 개선을 시도해 봅시다.
우선 수집서버에 APM 에이전트를 설치하고 하루 동안 수집된 데이터를 조회해봤습니다.
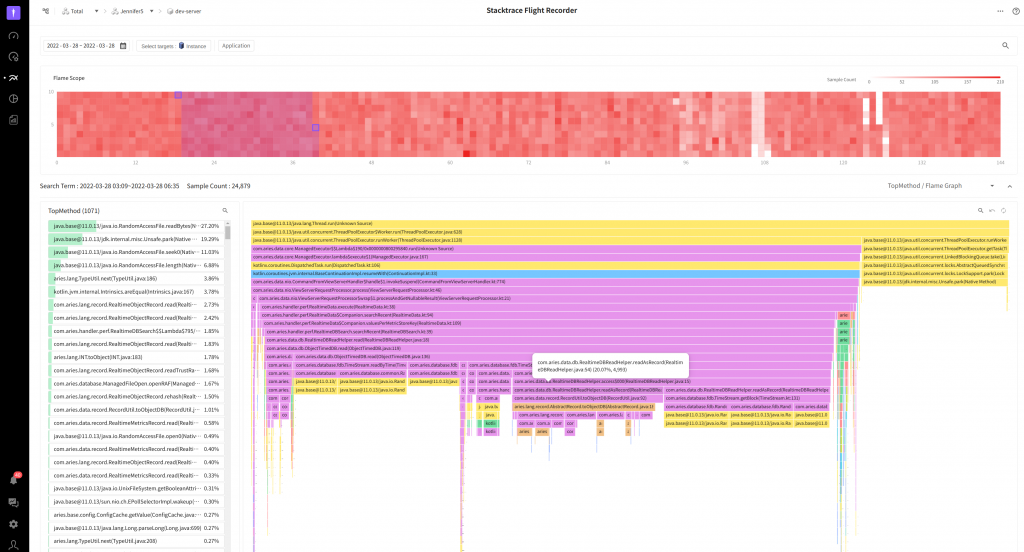
FlameScope 의 빨간 부분을 드래그 해보니 TopMethod 에 표시된 내용을 토대로 RandomAccessFile 읽기에 대부분의 시간이 소요되었음을 확인할 수 있습니다. 지속적인 파일 읽기가 시도된 것이 원인일 것입니다.
개선 시도 – 1
대부분의 시간이 파일 읽기에서 소요되고 있는데 어떻게 이것을 더 빠르게 할 수 있을까요?
자바에도 파일을 메모리에 직접 매핑하여 읽고 쓰는 메모리 맵 파일 구현(Memory-Mapped File)을 할 수 있지만 주의를 기울여야 하는 부분이 다소 존재하기에 다른 부분을 좀 더 살펴봅시다.
여기서는 분홍색 영역이 가장 너비가 넓은데 이 가운데 AbstractRecord.toObjectDB 라는 부분이 눈에 띕니다.

하위 메소드들은 RealtimeObjectRecord.read 로 InputStream 으로부터 바이트를 정해진 순서대로 읽어 객체로 변환하는 내용을 담고 있습니다.
이 부분이 총 19.05% 를 차지하고 있으니 여기를 빠르게 하면 성능이 조금 나아지지 않을까라는 생각이 듭니다.
protected IRecord read(InputStream in, boolean db) {
if (!db) {
this.time = TcpUtil.getlong(in);
}
this.otype = TcpUtil.getbyte(in);
this.oid = TcpUtil.getint(in);
int count = TcpUtil.getshort(in);
for (int t = 0; t < count; t++) {
short key = TcpUtil.getshort(in);
TYPE value = TypeUtil.next(in);
this.putValue(key, value);
}
readTrustRangePart(count, in);
return this;
}
“딱히 개선할 부분이 없어보이는데.. NIO 의 바이트 버퍼를 이용하면 좀 더 괜찮지 않을까? 혹여나 메모리 맵을 쓰게 되다면 중간 변환 단계도 없앨 수 있고..“
바이트를 핸들링하기도 더 편하기도 하니 ByteBuffer 를 이용하는 방법으로 변경해보았습니다.
@Override
public IRecord read(ByteBuffer bb, boolean db) {
if (!db) {
this.time = bb.getLong();
}
this.otype = bb.get();
this.oid = bb.getInt();
int count = bb.getShort();
for (int t = 0; t < count; t++) {
short key = bb.getShort();
TYPE value = TypeUtilV2.next(bb);
this.putValue(key, value);
}
return this;
}
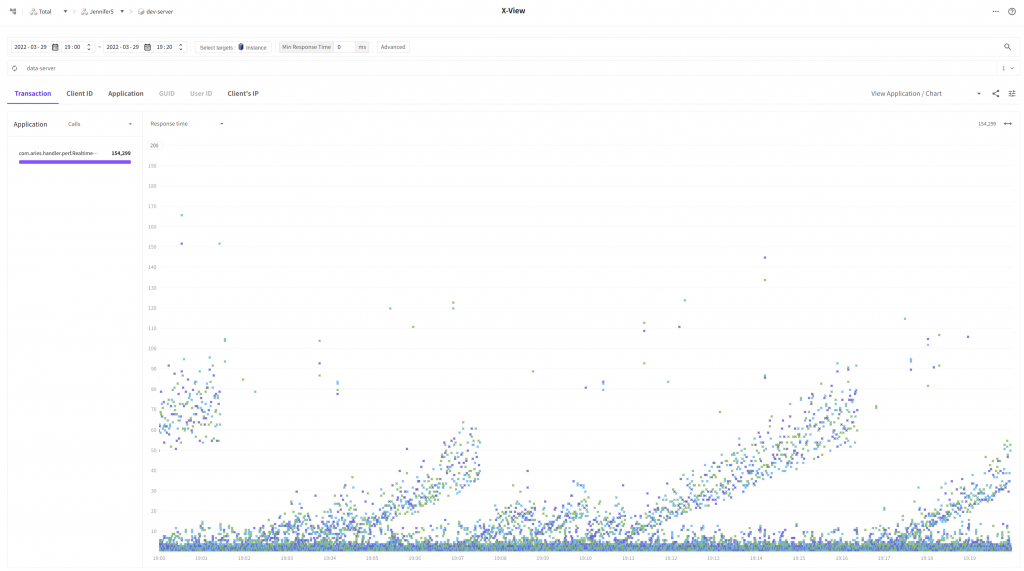
변경된 코드를 반영하고 다시 조회된 결과를 확인해볼까요?

음.. 우선 FlameScope 의 색상이 전보다 옅어졌습니다.
이것은 어느정도 스레드에서 수행되는 태스크의 시간이 전보다 짧아졌음을 암시합니다.
하단의 FlameGraph 에서는 AbstractRecord.toObjectDB 가 차지하는 비율이 9.03% 인 것을 확인할 수 있습니다. 수치상이긴 하지만 10% 가량 호출 빈도가 감소했습니다!
이번엔 X-View 차트로 비교해보면 어떨까요?
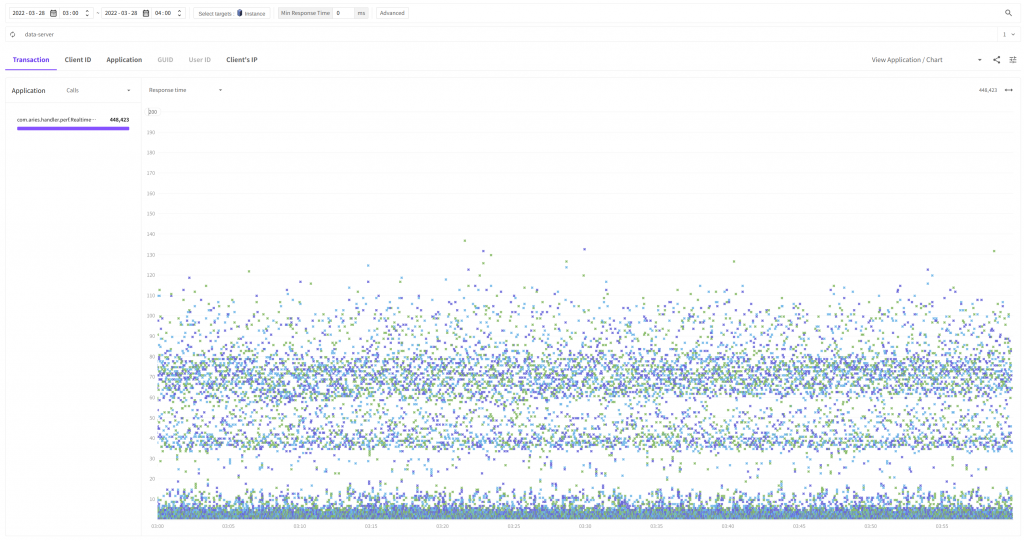
- 개선 후
마치 파도와 같은 너울 모양이 눈에 들어오기는 하지만 40ms ~ 110ms 사이의 분포가 많이 사라진 것을 확인할 수 있습니다. 생각보다 많은 수의 요청 응답시간이 개선되었습니다!
개선시도 – 2
이쯤에서 멈출 수도 있었지만 Y 씨는 파도처럼 위쪽에 남아있는 트랜잭션의 응답시간도 아래쪽으로 내려보고 싶다는 욕구를 참을 수가 없었습니다.
조금더 노력을 기울여 개선시도 – 1 에서 언급한 Memory-Mapped File 을 이용해서 읽기 부분을 변경했습니다.
private val map = inner.raf().channel.map(FileChannel.MapMode.READ_ONLY, 0, inner.length())
구현의 간단함을 추구하기 위해 읽기 전용 메모리 맵을 썼습니다.
두근거리는 마음을 가라 앉히고 코드를 반영한 Y 씨는 SFR 화면으로 이동하여 조회 버튼을 눌렀습니다!

오오.. 이제는 TopMethod 에 RandomAccess 관련 내용이 거의 보이지 않습니다!
X-View 로 조회했을때도 차이가 있을까요?
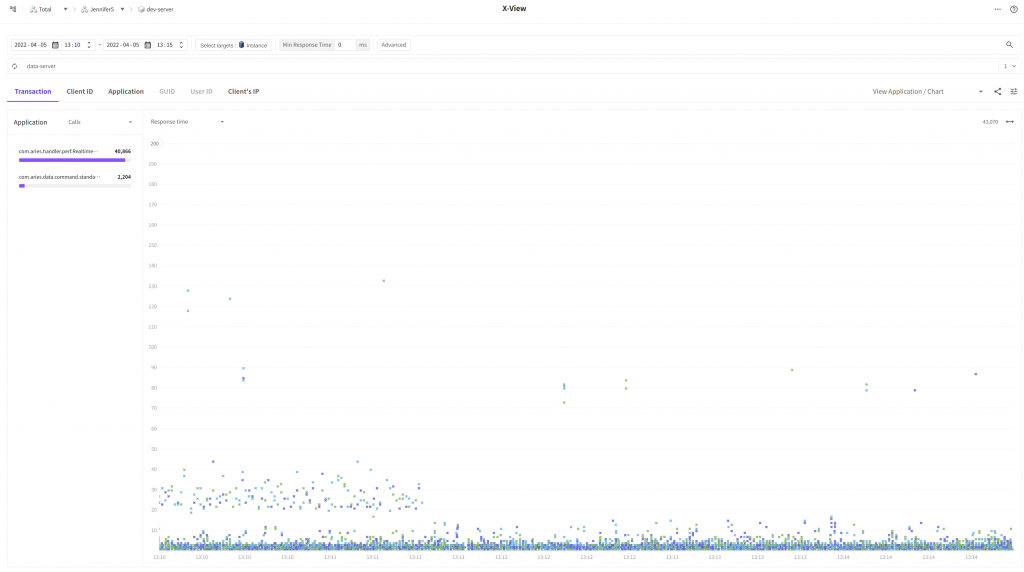
드디어 일부 트랜잭션을 제외한 대다수의 트랜잭션의 응답시간이 10ms 미만으로 감소했습니다.
이로써 대시보드 차트의 조회 성능이 개선되었음을 확신할 수 있습니다.
이제 이슈로 올라왔던 개별 요청이 느린..(불과 200ms 이라 할지라도..) 현상은 크게 개선될 수 있을 것입니다. 권고안을 벗어난 다수의 요청에도 어느 정도는 잘 처리할 수 있겠죠?!
결론
과거 프로파일에만 의존하여 성능개선을 할때 겪었던 여러일들이 기억에 남습니다.
프로파일이 너무 많아 제대로 조회하기도 힘들때도 있었고 조회된 프로파일의 개별 응답시간이 너무 작아서 분석에 애를 먹기도 했습니다.
그럴때마다 성능분석 도구를 만들고 있음에도 로그에 각종 단서를 출력하거나 다른 분석도구에 의존할 수 밖에 없는 현실을 극복하고 싶었습니다.
상당 기간동안 VisualVM 의 소스코드도 읽어보고 다수의 오픈소스를 찾아보며 제대로 된 스택트레이스 기반 분석 도구를 찾아 해매기도 했습니다.
당시 샘플링은 지금보다 더 생소한 개념이었기에 하나의 아이디어가 기능으로 만들어지기까지 5년도 넘는 시간이 걸렸다는 점에서 아쉬움이 남습니다.
기능을 기획하고 개발하면서 오랜 기간동안 샘플링이라는 기능의 사용자로서 겪은 경험을 최대한 반영하려 노력했습니다.
SFR은 저의 경험, 동료 개발자의 공감, 제품 디자이너와의 열띤 토론의 결과입니다.
개발하면서 그리고 직접 이용해보면서 경험한 개선 효과를 더 많은 사용자들이 누릴 수 있기를 바라며 본 글을 마칩니다.
